

Różnica między Hadoop i SQL
- 1332
- 35
- Łukasz Kalisz
Termin „Big Data” jest jednym z najgorętszych modnych słów w dzisiejszej erze cyfrowej. Każda firma od małych startupów po duże przedsiębiorstwa ma pieniądze na duże zbiory danych. Nagle widzimy zbieżność znaczących trendów, które zasadniczo przekształcają branżę i istnieje eksplozja danych ze względu na rosnącą liczbę urządzeń podłączonych do Internetu. Big Data to dokładnie miejsce, w którym do obrazu przychodzi framework open source. Hadoop zapewnia ramy do przechowywania i pobierania ogromnych ilości danych do celów przetwarzania i analitycznych. Ale jak Hadoop różni się od innych systemów zarządzania bazami danych, takimi jak SQL Server? Podkreślamy niektóre kluczowe różnice między SQL i Hadoop.
Co to jest Hadoop?
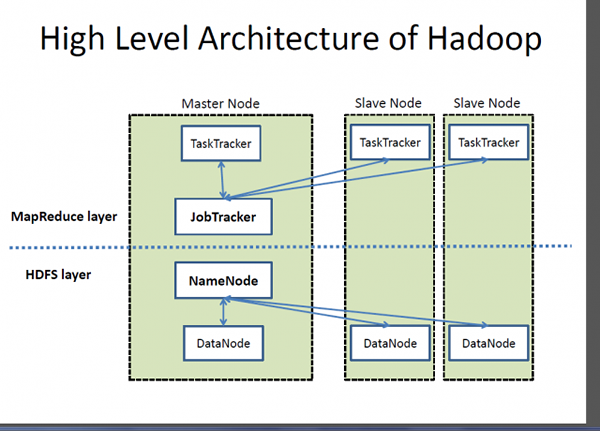
Hadoop to open source rozproszone ramy przetwarzania zaprojektowane w celu zaspokojenia potrzeb firm internetowych do indeksowania i przetwarzania ogromnych ilości danych, dzięki uprzejmości rosnącego wzrostu urządzeń obsługiwanych przez Internet i kolejnej dużej ewolucji o nazwie Media Social Media. Google stanowi inspirację dla rozwoju, który stał się znany jako Hadoop. Zapewnia strukturę, która umożliwia przetwarzanie masywnych objętości danych w celu zapewnienia łatwego dostępu i dynamicznego ładowania danych.
Co to jest SQL?
SQL było wszechobecnym narzędziem do uzyskiwania dostępu do danych w bazie danych. SQ Server nie jest już regularnym systemem zarządzania bazami danych używanymi przez programistów i administratorów i analityków baz danych. Jest to ogromny ekosystem narzędzi i usług różnicowych, które działają w połączeniu w celu zapewnienia bardzo złożonych zadań zarządzania platformą danych. Jest to de facto język systemów wsparcia transakcyjnego i decyzji oraz narzędzia inteligencji biznesowej, aby uzyskać dostęp do zapytania o różne źródła danych. W rzeczywistości SQL Server obsługuje wymuszanie jakości i spójności danych znacznie lepiej niż Hadoop.
Różnica między Hadoop i SQL
Narzędzie
- Hadoop jest projektem Apache Software Foundation i open source rozproszonym programem oprogramowania do przechowywania i przetwarzania masywnego napływu danych i uruchamiania aplikacji na klastry sprzętu towarowego. Hadoop zapewnia strukturę, która pozwala na przetwarzanie masywnych objętości danych w celu zapewnienia łatwego dostępu i dynamicznego ładowania danych. Z drugiej strony SQL, skrót od ustrukturyzowanego języka zapytań, jest de facto językiem dla systemów wsparcia transakcyjnego i decyzji oraz narzędzi analizy biznesowej w celu uzyskiwania dostępu do różnych danych z różnych źródeł. SQL było wszechobecnym narzędziem do dostępu, manipulowania i przechowywania danych w bazie danych.
Ramy Hadoop vs. SQL
- U podstaw ekosystemu Hadoop znajdują się dwa główne komponenty - system plików rozproszony Hadoop (HDFS) - rozproszony, skalowalny i przenośny system plików napisany w Javie do przechowywania bardzo dużych zestawów danych w klastrach komputerów; oraz podejście do rozproszonego przetwarzania oparte na Javie o nazwie MapReduce. Z drugiej strony SQL Server to relacyjny system zarządzania bazą danych i jedną z najpotężniejszych na świecie platform danych używanych przez szereg produktów komercyjnych i wewnętrznych do zapytania, manipulowania i wizualizacji różnych źródeł danych.
Typ danych
- Hadoop został zaprojektowany do pracy z dowolnym typem danych, niezależnie od tego, czy jest on ustrukturyzowany, częściowo ustrukturyzowany, czy nieustrukturyzowany, co czyni go bardzo elastycznym w pracy, jeśli chodzi o przetwarzanie dużych zbiorów danych. Z drugiej strony SQL to język programowania specjalnie utworzony do zarządzania i zapytania w relacyjne systemy zarządzania bazami danych (RDBMS). Opiera się na modelu relacji encji RDBMS, więc może tylko przetwarzać dane ustrukturyzowane. SQL nie może być używane do danych nieustrukturyzowanych, ponieważ nie są one zgodne z modelem danych bez możliwej do zidentyfikowania struktury.
Przetwarzanie
- HDFS to rozproszony system plików zaprojektowany do obsługi przetwarzania partii danych, co oznacza, że dane są gromadzone w partiach, a każda partia jest wysyłana do przetwarzania. Partia może być od jednego dnia do jednej minuty. Ponieważ jest przeznaczony do przetwarzania wsadowego, nie ma koncepcji losowych odczytów ani zapisów. SQL Server, wręcz przeciwnie, jako platforma bazy danych ogólnej, obsługuje przetwarzanie danych w czasie rzeczywistym, co oznacza, że dane są przesyłane od nadawcy do odbiornika, gdy tylko zostaną opracowane na końcu źródła.
Wydajność Hadoop i SQL
- Architektura Hadoopa czasami prowadzi do niedopasowania impedancji między przechowywaniem danych a dostępem do danych. Ma mniej ograniczeń lub walidacji na przechowywane przez niego dane, i nie ma takich samych możliwości i ekosystemu użytkownika końcowego, które opracował SQL. Z drugiej strony SQL Server obsługuje wymuszanie jakości i spójności danych znacznie lepiej niż Hadoop, co umożliwia wykorzystanie ekosystemu analizy danych opartych na SQL i narzędzi do wizualizacji danych. Jednak SQL ma również pewne wady, które obejmują skalowalność do obsługi ogromnych ilości danych i obsługę przechowywania luźno sformatowanych danych.
Hadoop vs. SQL: Wykres porównawczy

Podsumowanie Hadoop vs. SQL
Hadoop jest najbardziej preferowanym i powszechnie akceptowanym narzędziem dużych zbiorów danych zaprojektowanych do pracy z dowolnym typem danych - nieustrukturyzowany lub częściowo ustrukturyzowany. Ale jeśli chodzi o RDBMS, SQL jest prawdopodobnie najpotężniejszym, w pamięci i dynamicznym systemie przechowywania danych i zarządzania. Jednak istniejące rozwiązania RDBMS, takie jak serwery SQL, służą wyłącznie do zarządzania znaczącym ilością danych, ale nie w przypadku danych nieustrukturyzowanych lub częściowo ustrukturyzowanych o zmiennych atrybutach. Podobnie jak w przypadku wielu platform, zarówno Hadoop, jak i SQL Server mają swój uczciwy udział w mocnych stronach i słabościach. Użyj ich oba razem, a możesz wykorzystać mocne strony podczas łagodzenia słabości.
- « Różnica między rozpoznawaniem mowy a przetwarzaniem języka naturalnego
- Różnica między biosensor i biochip »