

Różnice między nadzorowanym uczeniem się a uczeniem się bez nadzoru
- 1538
- 251
- Krystyna Urbanowicz
Uczniowie dążenia do uczenia maszynowego mają trudności z odróżnieniem nadzorowanego uczenia się od uczenia się bez nadzoru. Wydaje się, że procedura zastosowana w obu metodach uczenia się jest taka sama, co utrudnia rozróżnienie dwóch metod uczenia się. Jednak po kontroli i niezachwianej uwagi można jasno zrozumieć, że istnieją znaczące różnice między uczeniem się nadzorowanym i bez nadzoru.
-
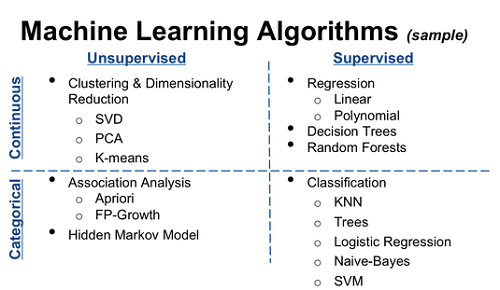
Czym jest naukę nadzorowaną?
Nadzorowane uczenie się jest jedną z metod związanych z uczeniem maszynowym, która obejmuje przydzielanie oznaczonych danych, aby z tych danych można wywnioskować określony wzór lub funkcja. Warto zauważyć, że nadzorowane uczenie się obejmuje przydzielenie obiektu wejściowego, wektora, a jednocześnie przewidując najbardziej pożądaną wartość wyjściową, która jest głównie określana jako sygnał nadzorczy. Najważniejszą właściwością nadzorowanego uczenia się jest to, że dane wejściowe są znane i odpowiednio oznaczone.
-
Czym jest uczenie się bez nadzoru?
Uczenie się bez nadzoru jest drugą metodą algorytmu uczenia maszynowego, w którym wnioski są wyciągnięte z nieznakowanych danych wejściowych. Celem uczenia się bez nadzoru jest określenie ukrytych wzorców lub grupowanie danych na podstawie nieoznaczonych danych. Jest to głównie wykorzystywane w analizie danych eksploracyjnych. Jednym z definiujących znaków uczenia się bez nadzoru jest to, że zarówno dane wejściowe, jak i wyjściowe nie są znane.
Różnice między nadzorowanym uczeniem się a uczeniem się bez nadzoru
-
Dane wejściowe w nadzorowanym uczeniu się i uczeniu się bez nadzoru
Podstawową różnicą między nadzorowanym uczeniem się a uczeniem się bez nadzoru są dane użyte w każdej metodzie uczenia maszynowego. Warto zauważyć, że obie metody uczenia maszynowego wymagają danych, które przeanalizują w celu uzyskania niektórych funkcji lub grup danych. Jednak dane wejściowe wykorzystywane w nadzorowanym uczeniu się są dobrze znane i są oznaczone. Oznacza to, że maszyna ma tylko za zadanie roli określania ukrytych wzorców na podstawie już oznaczonych danych. Jednak dane wykorzystane w uczeniu się bez nadzoru nie są znane ani oznaczone. Praca maszyny jest kategoryzacja i oznaczenie surowych danych przed określeniem ukrytych wzorców i funkcji danych wejściowych.
-
Złożoność obliczeniowa w nadzorowanym uczeniu się i uczeniu się bez nadzoru
Uczenie maszynowe jest złożoną sprawą i każda zaangażowana osoba musi być przygotowana na przede wszystkim zadanie. Jedną z wyróżniających się różnic między nadzorowanym uczeniem się a uczeniem się bez nadzoru jest złożoność obliczeniowa. Uczenie się nadzorowane jest uważane za złożoną metodę uczenia się, podczas gdy bez nadzoru metody uczenia się jest mniej złożone. Jednym z powodów, dla których sprawuje, że nadzorowany romans uczenia się jest fakt, że trzeba zrozumieć i oznaczyć dane wejściowe podczas uczenia się bez nadzoru, nie trzeba zrozumieć i oznaczać danych wejściowych. To wyjaśnia, dlaczego wiele osób wolało uczenie się bez nadzoru w porównaniu z nadzorowaną metodą uczenia maszynowego.
-
Dokładność wyników nadzorowanego uczenia się i uczenia się bez nadzoru
Inną dominującą różnicą między uczeniem się nadzorowanym a uczeniem się bez nadzoru jest dokładność wyników uzyskanych po każdym cyklu analizy maszyn. Wszystkie wyniki wygenerowane z nadzorowanej metody uczenia maszynowego są bardziej dokładne i niezawodne w porównaniu z wynikami wygenerowanymi z bez nadzoru metody uczenia maszynowego. Jednym z czynników, który wyjaśnia, dlaczego nadzorowana metoda uczenia maszynowego daje dokładne i wiarygodne wyniki, jest to, że dane wejściowe są dobrze znane i oznaczone, co oznacza, że maszyna będzie analizować tylko ukryte wzorce. Nie jest to inaczej niż bez nadzoru metody uczenia się, w której maszyna musi zdefiniować i oznaczyć dane wejściowe przed określeniem ukrytych wzorców i funkcji.
-
Liczba zajęć w nadzorowanym uczeniu się i uczeniu się bez nadzoru
Warto również zauważyć, że istnieje znacząca różnica, jeśli chodzi o liczbę klas. Warto zauważyć, że wszystkie klasy stosowane w nadzorowanym uczeniu się są znane, co oznacza, że odpowiedzi w analizie mogą być znane. Jedynym celem nadzorowanego uczenia się jest zatem określenie nieznanego klastra. Jednak nie ma wcześniejszej wiedzy na temat bez nadzoru metody uczenia maszynowego. Ponadto liczba klas nie jest znana, co wyraźnie oznacza, że żadne informacje nie są znane, a wyników generowanych po analizie nie można ustalić. Ponadto osoby zaangażowane w bez nadzoru metody uczenia się nie są świadome żadnych informacji dotyczących surowych danych i oczekiwanych wyników.
-
Uczenie się w czasie rzeczywistym w nauce nadzorowanej i uczenia się bez nadzoru
Wśród innych różnic istnieje czas, po którym odbywa się każda metoda uczenia się. Ważne jest, aby podkreślić, że nadzorowana metoda uczenia się odbywa się offline, podczas gdy w czasie rzeczywistym odbywa się bez nadzoru metody uczenia się. Osoby zaangażowane w przygotowanie i etykietowanie danych wejściowych wykonują to offline, podczas gdy analiza ukrytego wzorca odbywa się online, co zaprzecza osobom zaangażowanym w uczenie maszynowe możliwość interakcji z maszyną podczas analizy danych dyskretnych. Jednak w czasie rzeczywistym odbywa się bez nadzoru uczenia maszynowego, tak że wszystkie dane wejściowe są analizowane i oznaczone w obecności uczniów, które pomagają im zrozumieć różne metody uczenia się i klasyfikacji danych surowych. Analiza danych w czasie rzeczywistym pozostaje najważniejszą zaletą bez nadzoru metody uczenia się.
Tabela pokazująca różnice między uczeniem się nadzorowanym a uczeniem się bez nadzoru: wykres porównawczy
| Nadzorowana nauka | Uczenie się bez nadzoru | |
| Dane wejściowe | Wykorzystuje znane i oznaczone dane wejściowe | Używa nieznanych danych wejściowych |
| Złożoność obliczeniowa | Bardzo złożony w obliczeniach | Mniej złożoności obliczeniowej |
| Czas rzeczywisty | Używa analizy off-line | Wykorzystuje analizę danych w czasie rzeczywistym |
| Liczba klas | Znana jest liczba klas | Liczba klas nie jest znana |
| Dokładność wyników | Dokładne i niezawodne wyniki | Umiarkowane dokładne i niezawodne wyniki |
Podsumowanie nadzorowanego uczenia się i uczenia się bez nadzoru
- Wydobycie danych staje się istotnym aspektem w obecnym świecie biznesu ze względu na zwiększone surowe dane, które organizacje muszą analizować i przetwarzać, aby mogły podejmować solidne i niezawodne decyzje.
- To wyjaśnia, dlaczego potrzeba uczenia maszynowego rośnie, a tym samym wymaga ludzi o wystarczającej wiedzy zarówno na temat nadzorowanego uczenia maszynowego, jak i bez nadzoru uczenia maszynowego.
- Warto zrozumieć, że każda metoda uczenia się oferuje własne zalety i wady. Oznacza to, że należy znaleźć obie metody uczenia maszynowego przed ustaleniem, która metoda będzie używać do analizy danych.