

Różnica między HBase a Hive
- 1939
- 576
- Salwator Słowiński
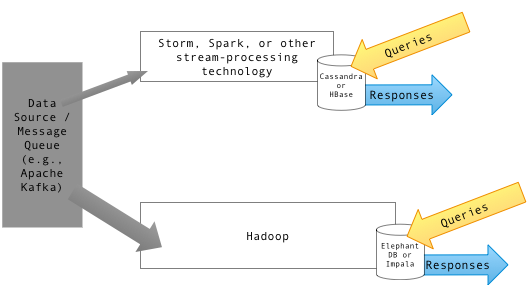
HBase i Hive to struktury magazynów danych oparte na Hadoop, które różnią się znacznie co do tego, jak przechowują i zapytają dane. Zarządzanie i przetwarzanie ogromnych ilości danych internetowych staje się coraz trudniejsze za pośrednictwem konwencjonalnych narzędzi do zarządzania bazami danych. Tutaj pojawia się HBASE. HBASE jest preferowanym wyborem do obsługi dużych ilości danych. Na przykład, jeśli chcesz filtrować przez ogromny magazyn e -maili, aby wyciągnąć jeden do kontroli lub w jakimkolwiek innym celu, będzie to idealny przypadek użycia dla HBase. Z drugiej strony Hive bardziej przypomina tradycyjny system raportowania hurtowni danych, który działa na szczycie Hadoop. Hive oferuje język zapytania podobny do SQL, który pozwala zapytać o częściowo ustrukturyzowane dane przechowywane w Hadoop. To wymaga niepotrzebnego wysiłku konieczności pisania kodu MapReduce. Chociaż zarówno HBase, jak i Hive są wykorzystywane jako magazyny danych do przechowywania nieustrukturyzowanych danych, są one różne.
Co to jest HBase?
HBASE to open source, niereacyjny system zarządzania bazą danych inspirowany dużą architekturą tabeli Google i napisaną w Javie. HBASE jest zasadniczo zorientowaną na kolumnę, rozproszoną bazę danych NoSQL, która działa na górze systemu plików rozproszonych Hadoop (HDFS). Jest zaprojektowany i opracowany przez wielu inżynierów w ramach Fundacji Apache Software Foundation. Znajduje się na Apache Hadoop i zasilany przez tolerancję na usterki rozproszonej struktury plików znaną jako HDFS. Zapewnia sposób przechowywania rzadkich zestawów danych, które są powszechne w przypadkach użycia dużych zbiorów danych. Umożliwia szybkie odczyty danych losowego dostępu z dużych ilości danych na podstawie kluczowych wartości. Nie jest jednak zaprojektowany do wykonywania agregacji danych.
Co to jest Hive?
Hive nie jest dokładnie bazą danych, ale pakiet hurtowni danych zbudowany na szczycie Hadoop. Hive to inna technologia niż HBASE; Struktury dane w zestawie tabel, które można łączyć, agregować i zapytać po użyciu języka zapytania o nazwie Hive Query Language (HQL), który jest bardzo podobny do SQL, używany do przetwarzania wsadowego dużych danych. Pozwala na przesłuchanie częściowo ustrukturyzowanych danych przechowywanych w Hadoop, które ostatecznie przekształca się w zadanie MapReduce, wykonane lokalnie lub w rozproszonym klastrze MapReduce. Hive jest zasadniczo systemem hurtowni danych dla Hadoop, który ułatwia łatwą podsumowanie danych, zapytania ad hoc i analizę dużych zestawów danych przechowywanych w systemach plików kompatybilnych z Hadoop. Dane można odczytać i zapisać z Hive i HBase i Viceversa. Nie można go jednak wykorzystać do przetwarzania danych w czasie rzeczywistym.
Różnica między HBase a Hive
Technologia
- Chociaż zarówno HBase, jak i Hive są strukturami magazynów danych opartych na Hadoop używanych do przechowywania i przetwarzania dużych ilości danych, różnią się one znacznie co do tego, jak przechowują dane dotyczące przechowywania i zapytania. HBASE jest zasadniczo zorientowaną na kolumnę, rozproszoną bazę danych NoSQL, która działa na górze systemu plików rozproszonych Hadoop (HDFS) i zapewnia odporne na awarie sposób przechowywanie rzadkich zestawów danych, które są powszechne w przypadku użycia dużych danych. Hive z drugiej strony nie jest dokładnie bazą danych, ale pakiet hurtowni danych zbudowany na szczycie Hadoop. Hive przypomina bardziej tradycyjny system raportowania hurtowni danych.
Architektura
- HBASE to baza danych NoSQL i implementacja open source dużej architektury tabeli Google, która znajduje się na Apache Hadoop i zasilana przez rozproszoną strukturę plików odporną na usterki znaną jako HDFS. Jest to skalowalne rozwiązanie do przechowywania, aby pomieścić praktycznie niekończącą się ilość danych. Jest to architektura przechowywania danych używana do przechowywania nieustrukturyzowanych danych. Z drugiej strony Hive to silnik SQL zbudowany na HDFS i wykorzystuje MAPREDUCE wewnętrznie, umożliwiając zapytanie danych przechowywanych na HDFS za pośrednictwem języka zapytania podobnego do SQL o nazwie HQL (język zapytania Hive).
Używać
- HBASE służy do budowy tanie, elastyczne i łatwe w utrzymaniu usług warstw kafelkowych - system informacji geograficznej oparty na Hadoop (HBGIS) - w celu masowego przechowywania danych. Jest to format przechowywania kolumn na dysk, który zapewnia sposób przechowywania rzadkich zestawów danych, które są powszechne w przypadkach użycia dużych zbiorów danych. Umożliwia szybkie odczyty danych losowego dostępu z dużych ilości danych na podstawie kluczowych wartości. Z drugiej strony Hive jest standardem dla zapytań SQL w stosunku do petabajtów danych w Hadoop i zapewnia język zapytań podobny do SQL o nazwie HQL do zapytań danych przechowywanych w klastrze Hadoop.
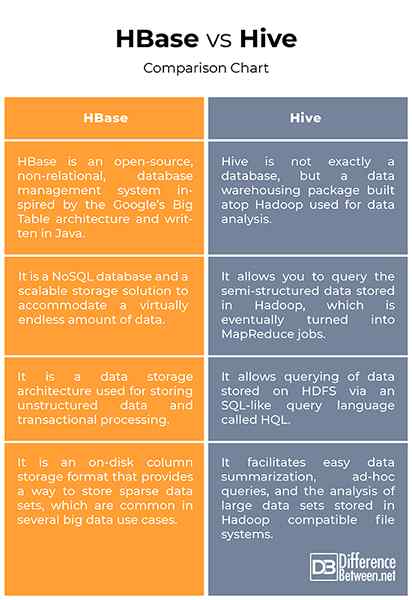
HBase vs. Hive: wykres porównawczy
Streszczenie
Chociaż zarówno HBase, jak i Hive są strukturami magazynów danych opartych na Hadoop używanych do przechowywania i przetwarzania dużych ilości danych, różnią się one znacznie co do tego, jak przechowują dane dotyczące przechowywania i zapytania. HBASE to zorientowany na kolumnę system zarządzania bazą danych używany do masywnego przechowywania danych i zapewnia sposób przechowywania rzadkich zestawów danych, które są powszechne w kilku przypadkach użycia dużych danych. Z drugiej strony Hive bardziej przypomina tradycyjny system raportowania hurtowni danych zbudowany na szczycie Hadoop używany do przetwarzania za pośrednictwem zadań harmonogramów, a następnie załadowania wyników do tabeli typu podsumowującego, które można dalej zapytać przez aplikacje klientów.