

Różnica między Hadoopem a MongoDB
- 1249
- 97
- Hilarion Porębski
Od dłuższego czasu słyszymy termin Big Data, ale czym dokładnie jest ten Big Data? Ilość danych wytwarzanych przez Internet przedmiotów dramatycznie wzrosła na przestrzeni lat i stale rośnie w tempie wykładniczym. Przetwarzanie tych masywnych objętości danych nie nadające się do tradycyjnych metod do obsługi jest określane jako Big Data. Tego rodzaju dane stanowią wyzwania dla tradycyjnych systemów RDBMS używanych do przechowywania i przetwarzania danych. Moc przetwarzania potrzebna do przechowywania i przetwarzania tak dużej ilości danych w sposób terminowy i opłacalny jest masywny. Aby rozwiązać ten problem, wymagane są nowe i ulepszone rozwiązania dużych zbiorów danych, które są specjalnie zaprojektowane do przetwarzania dużych nieustrukturyzowanych danych. Spośród wielu technologii Hadoop i MongoDB to dwie popularne opcje, jeśli chodzi o przechowywanie i przetwarzanie dużych zbiorów danych. Chociaż oba są dość podobne w zasadzie tego, co robią, ale ich podejście do tego, jak to robią, jest zupełnie inne. Spójrz na „.
Co to jest MongoDB?
MongoDB to baza danych z dokumentami typu open source, która stała się de facto bazą danych nosql z milionami użytkowników, od małych startupów po firmy z listy Fortune 500. Wiodące przedsiębiorstwa i firmy konsumenckie wykorzystują możliwości MongoDB w swoich produktach i rozwiązaniach. Napisany w C ++, MongoDB to międzyplatforma, zorientowana na dokument baza danych, która skutecznie zajmuje się ograniczeniami baz danych opartych na schemach SQL, zapewniając wysoką wydajność, wysoką dostępność i łatwą skalowalność rozwiązań. Jest to baza danych zaprojektowana dla nowoczesnej sieci. Podobnie jak inne bazy danych NoSQL, MongoDB nie jest zgodne z zasadami RDBMS bez koncepcji tabel, wierszy i kolumn. Przechowuje swoje dane w dokumentach BSON, w których wszystkie powiązane dane są umieszczane razem w jednym dokumencie.
Co to jest Hadoop?
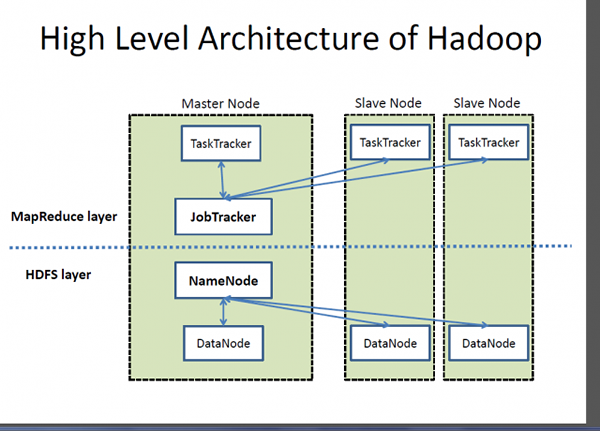
Hadoop to struktura typu open source zaprojektowana do przechowywania i przetwarzania masywnych objętości danych w klastrach komputerów. Jest to aplikacje oparte na Javie i zbiór różnych oprogramowania, które tworzy framework przetwarzania danych. Chodzi o to, aby przetwarzać dane na dużą skalę po rozsądnych kosztach w jak najmniejszym czasie. Hadoop składa się z trzech podstawowych zasobów: Hadoop rozproszonego systemu plików (HDFS), platformy programowania Mapreduce Google i całego ekosystemu Hadoop Hadoop. Ekosystem Hadoop składa się z modułów, które pomagają programować system, zarządzać i konfigurować klaster, zarządzać i przechowywać dane w klastrze oraz wykonywać zadania analityczne. Hadoop MapReduce AIDS Analityka danych Proces bardzo dużych ilości danych ustrukturyzowanych i nieustrukturyzowanych. Hadoop jest zarejestrowanym znakiem towarowym oprogramowania Apache Foundaton, a MapReduce jest jego ramą do równoległego przetwarzania.
Różnica między Hadoopem a MongoDB
Platforma
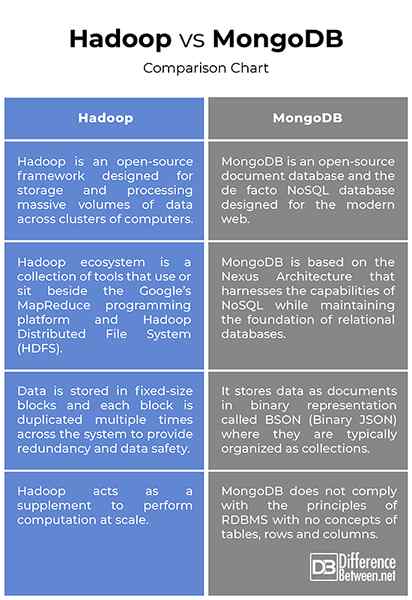
- Chociaż oba są uważane za rozwiązania Big Data, MongoDB jest zasadniczo platformą ogólnego przez. MongoDB to baza danych dokumentów typu open source i jedna z wiodących baz danych NoSQL, która wykorzystuje dokumenty, zamiast wierszy i tabel, aby była elastyczna, skalowalna i szybka. Z drugiej strony Hadoop to ramy typu open source zaprojektowane do przechowywania i przetwarzania masywnych objętości danych w klastrach komputerów. Hadoop nie ma na celu zastąpienia istniejących systemów RDBMS; W rzeczywistości działa jako suplement w celu wspomagania analizy danych w przetwarzaniu dużych objętości danych ustrukturyzowanych i nieustrukturyzowanych.
Architektura
- Hadoop Ecosystem to zbiór narzędzi, które używają lub siedzą obok platformy programowania MapReduce Google i HDFS (Hadoop rozproszony system plików) do przechowywania i organizowania danych oraz zarządzania maszynami prowadzącymi Hadoop Hadoop. HDFS jest przeznaczony do strumieniowego dostępu do danych. Z drugiej strony MongoDB oferuje inne podejście; Opiera się na architekturze Nexusa, która wykorzystuje możliwości NoSQL, zachowując podstawę relacyjnych baz danych. Przechowuje dane jako dokumenty w reprezentacji binarnej o nazwie BSON (binarne JSON), w których są one zwykle zorganizowane jako kolekcje.
Wytrzymałość
- Największą siłą Hadoop jest MapReduce. Dzisiaj Hadoop jest najlepszymi ramami MapReduce na rynku. Koncepcja stojąca za MapReduce polega na tym, że dane wejściowe można podzielić na logiczne kawałki, w których każda część może być niezależnie przetworzona przez zadanie mapy. Zadanie mapy może działać w dowolnym węźle obliczeniowym w klastrze, a wiele zadań mapy może działać równolegle przez klaster. Z drugiej strony MongoDB to baza danych dokumentów, która może obsługiwać obciążenia, od startupowych MVP i POC po aplikacje przedsiębiorstwa z setkami serwerów. MongoDB rozwinął się z niszowego rozwiązania bazy danych de facto bazy danych. Jego pojęcie dokumentów jest naprawdę wyraziste i elastyczne.
Hadoop vs. MongoDB: wykres porównawczy
Streszczenie
Chociaż oba są dość podobne w zasadzie tego, co robią, ale ich podejście do tego, jak to robią, jest zupełnie inne. MongoDB przechowuje dane jako dokumenty w reprezentacji binarnej o nazwie BSON, podczas gdy w Hadoop dane są przechowywane w blokach o stałej wielkości, a każdy blok jest wielokrotnie powielany. Hadoop Ecosystem to zbiór narzędzi, które używają lub siedzą obok platformy programowania MapReduce Google, podczas gdy MongoDB oparty na architekturze Nexus, która wykorzystuje możliwości NoSQL, zachowując podstawę relacyjnych baz danych.