

Różnica między Hadoopem a Sparkem
- 943
- 225
- Pan Antonina Ruciński
Jednym z największych problemów w odniesieniu do dużych zbiorów danych jest to, że znaczna ilość czasu spędza na analizie danych obejmujących identyfikację, oczyszczanie i integrację danych. Duże tomy danych i wymóg analizy danych prowadzą do nauki o danych. Ale często dane są rozproszone w wielu aplikacjach biznesowych i systemach, które sprawiają, że są trochę trudne do analizy. Tak więc dane muszą zostać ponownie zaprojektowane i sformatowane, aby ułatwić analiza. Wymaga to bardziej wyrafinowanych rozwiązań, aby informacje były bardziej dostępne dla użytkowników. Apache Hadoop jest jednym z takich rozwiązań używanych do przechowywania i przetwarzania dużych zbiorów danych, wraz z wieloma innymi narzędziami dużych zbiorów danych, w tym Apache Spark. Ale który jest odpowiednim ramy do przetwarzania i analizy danych - Hadoop lub Spark? Dowiedzmy Się.
Apache Hadoop
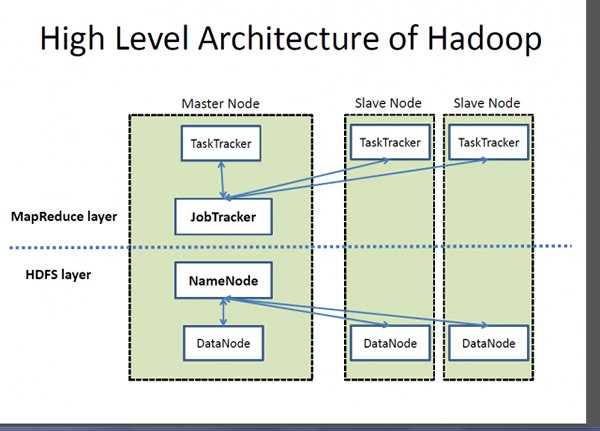
Hadoop jest zarejestrowanym znakiem towarowym Apache Software Foundation oraz ramą open source zaprojektowaną do przechowywania i przetwarzania bardzo dużych zestawów danych w klastrach komputerów. Obsługuje dane o bardzo dużej skali po rozsądnych kosztach w rozsądnym czasie. Ponadto zapewnia również mechanizmy poprawy wydajności obliczeń na skalę. Hadoop zapewnia strukturę obliczeniową do przechowywania i przetwarzania dużych zbiorów danych za pomocą modelu programowania Mapreduce Google. Może działać z pojedynczym serwerem lub może się skalować, w tym tysiące maszyn towarowych. Chociaż Hadoop został opracowany w ramach projektu open source w ramach Fundacji oprogramowania Apache opartego na paradygmatach MapReduce, dziś istnieje wiele rozkładów dla Hadoop. Jednak MapReduce jest nadal ważną metodą stosowaną do agregacji i liczenia. Podstawową ideą, na której opiera się MapReduce, jest równoległe przetwarzanie danych.

Apache Spark
Apache Spark to silnik komputerowy klastra open source i zestaw bibliotek do przetwarzania danych na dużą skalę na klastrach komputerowych. Zbudowany na modelu Hadoop MapReduce, Spark jest najbardziej aktywnie rozwijanym silnikiem open source, aby analiza danych była szybsza i zwiększała działalność programów. Umożliwia analizy w czasie rzeczywistym i zaawansowane na platformie Apache Hadoop. Rdzeniem Spark jest silnik obliczeniowy składający się z planowania, rozpowszechniania i monitorowania, które składają się z wielu zadań obliczeniowych. Jego kluczowym celem jest zaoferowanie ujednoliconej platformy do pisania aplikacji dużych zbiorów danych. Spark urodził się pierwotnie w laboratorium APM na University of Berkeley, a teraz jest to jeden z najlepszych projektów open source w ramach Portfolio of Apache Software Foundation. Jego niezrównane funkcje obliczeniowe w pamięci umożliwiają analityczne aplikacje do 100 razy szybciej na Apache Spark niż inne podobne technologie na rynku.
Różnica między Hadoopem a Sparkem
Struktura
- Hadoop jest zarejestrowanym znakiem towarowym Apache Software Foundation oraz ramą open source zaprojektowaną do przechowywania i przetwarzania bardzo dużych zestawów danych w klastrach komputerów. Zasadniczo jest to silnik przetwarzania danych, który w rozsądnym czasie obsługuje dane o bardzo dużej skali. Apache Spark to silnik komputerowy klastra open source zbudowany na modelu MapReduce Hadoopa do przetwarzania danych na dużą skalę i analizę w klastrach komputerowych. Spark umożliwia analiza w czasie rzeczywistym i zaawansowaną na platformie Apache Hadoop w celu przyspieszenia procesu obliczeniowego Hadoop.
Wydajność
- Hadoop jest napisany w Javie, więc wymaga pisania długich wierszy kodu, co zajmuje więcej czasu na wykonanie programu. Pierwotnie rozwinięte wdrożenie MapReduce było innowacyjne, ale także dość ograniczone, a także niezbyt elastyczne. Z drugiej strony Apache Spark jest napisany zwięzłym, eleganckim językiem Scala, aby programy działały łatwiejsze i szybsze. W rzeczywistości jest w stanie uruchomić aplikacje do 100 razy szybciej niż nie tylko Hadoop, ale także inne podobne technologie na rynku.
Łatwość użycia
- Hadoop MapReduce Paradigm jest innowacyjny, ale dość ograniczony i nieelastyczny. Programy MAPREDUCE są uruchamiane w partii i są przydatne do agregacji i liczenia na dużą skalę. Z drugiej strony Spark zapewnia spójne, kompozytowe interfejsy API, które można wykorzystać do budowy aplikacji z mniejszych elementów lub z istniejących bibliotek. API Spark są również zaprojektowane tak, aby umożliwić wysoką wydajność poprzez optymalizację różnych bibliotek i funkcji złożonych razem w programie użytkowników. A ponieważ Spark buforuje większość danych wejściowych w pamięci, dzięki RDD (Resilient rozproszony zestaw danych) eliminuje potrzebę ładowania wiele razy do pamięci i pamięci dyskowej.
Koszt
- System plików Hadoop (HDFS) to opłacalny sposób przechowywania dużych ilości danych zarówno ustrukturyzowanych, jak i nieustrukturyzowanych w jednym miejscu do głębokiej analizy. Koszt Hadoop na terabajt jest znacznie niższy niż koszt innych technologii zarządzania danymi, które są szeroko wykorzystywane do utrzymania hurtowni danych przedsiębiorstwa. Z drugiej strony Spark nie jest dokładnie lepszą opcją, jeśli chodzi o wydajność kosztową, ponieważ wymaga dużej ilości pamięci RAM, aby buforować dane w pamięci, co zwiększa klaster, stąd koszt nieznacznie, w porównaniu z Hadoopem.
Hadoop vs. Spark: Mapa porównawcza

Podsumowanie Hadoop vs. Iskra
Hadoop jest nie tylko idealną alternatywą do przechowywania dużych ilości strukturalnych i nieustrukturyzowanych danych w opłacalny sposób, ale także zapewnia mechanizmy poprawy wydajności obliczeń na dużą skalę. Chociaż został pierwotnie opracowany jako projekt Fundacji Open Source Apache Software Foundation oparty na modelu MapReduce Google, istnieje wiele różnych rozkładów dla Hadoop. Apache Spark został zbudowany na modelu MapReduce, aby rozszerzyć jego wydajność, aby wykorzystać więcej rodzajów obliczeń, w tym przetwarzanie strumienia i interaktywne zapytania. Spark umożliwia analiza w czasie rzeczywistym i zaawansowaną na platformie Apache Hadoop w celu przyspieszenia procesu obliczeniowego Hadoop.