

Różnica między Hadoopem a Cassandrą
- 2004
- 274
- Łukasz Kalisz
Dzięki ogromnym ilościom danych, które są generowane z bardzo dużą prędkością przez ogromną eksplozję Internetu przedmiotów i rosnące wykorzystanie mediów społecznościowych, zdolność do przechowywania i analizy tych ogromnych ilości danych wzrosła. Hadoop jest jednym z wyrafinowanych narzędzi zaprojektowanych do obsługi tak dużych danych, które często nazywane są Big Data. Cassandra to kolejna wysoce skalowalna baza danych, która jest łatwa do wdrożenia i zarządzania. Ale co jest najlepszym wyborem - Hadoop lub Cassandra?
Co to jest Hadoop?
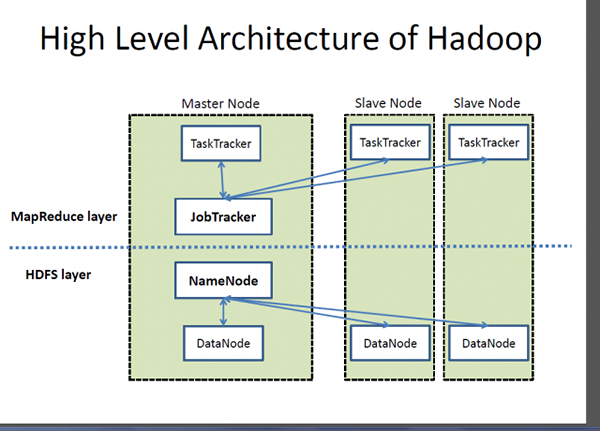
Apache Hadoop jest de facto framework do przetwarzania i przechowywania dużych ilości danych, które są często określane jako „duże zbiory danych”. Hadoop jest kamieniem węgielnym wszystkich rozwiązań Big Data. Projekt Fundacji Apache Software, Hadoop to duża rozproszona system przetwarzania zaprojektowana do rozpowszechniania i przetwarzania dużych ilości danych w węzłach w klastrze. Nie ma na celu zastąpienia tradycyjnych systemów bazy danych; W rzeczywistości Hadoop ułatwia korzystanie z relacyjnych baz danych poprzez przyspieszenie operacji związanych z dużymi zestawami danych. Hadoop opiera się na słynnym modelu programowania MapReduce odpowiedni do przetwarzania ogromnych zestawów danych, dystrybuowany przez klaster węzłów, równolegle. Hadoop rozproszony system plików (HDFS) to przechowywanie danych i przetwarzanie systemu plików dla Hadoop, który działa na sprzęcie towarowym i zapewnia równoległe, strumieniowe dostęp do dużych ilości danych.
Co to jest Cassandra?
Apache Cassandra to baza danych open source, w pełni rozpowszechniona, zorientowana na kolumnę. Cassandra to nierelacyjna baza danych, zwana także bazą danych NoSQL, która opiera jej projekt dystrybucji na Dynamo Amazon i model danych na BigTable Google - wysokowydajny baza danych NoSQL zbudowana na zastrzeżonych technologiach pamięci Google dla dużych infrastruktur baz danych. Jest to rozproszony system zarządzania zaprojektowany do obsługi dużych ilości strukturalnych danych na serwerach towarowych. W porównaniu z innymi popularnymi rozproszonymi bazami danych, takimi jak HBase, Voldermort i RIAK, Apache Cassandra oferuje solidny i ekspresyjny interfejs do modelowania i zapytania danych. Najlepsze w Cassandrze jest to, że jest rozpowszechniana, co oznacza, że jest w stanie działać na wielu maszynach.
Różnica między Hadoopem a Cassandrą
Definicja
- Hadoop jest ramą Apache Open-Source napisaną w Javie, która została zaprojektowana do obsługi dużych ilości danych, które należy przetwarzać na skalę, gdy przetwarzasz dużo danych w tym samym czasie w sposób przesyłania strumieniowego lub w stylu partii. Z drugiej strony Apache Cassandra to wysoce skalowalna, w pełni rozpowszechniona baza danych zaprojektowana do obsługi dużych ilości strukturalnych danych na serwerach towarowych. Apache Cassandra oferuje solidny i ekspresyjny interfejs do modelowania i zapytania.
Zastosowanie
- Hadoop to skalowalna struktura, która jest zaprojektowana do wdrażania na taniego sprzętu. Pamięć HDFS jest rozłożona na klastrze węzłów; Pojedynczy duży plik może być przechowywany w wielu węzłach w klastrze. Jest wdrażany w jednym centrum danych, ale wszystkie są zlokalizowane geograficznie. Z drugiej strony Cassandra jest wdrażany w bardzo rozproszony sposób jako klaster instancji, które wszystkie są świadomi siebie. Dane można odczytać lub zapisać w dowolnej instancji w klastrze, określane jako węzeł, który przekazał żądanie do instancji, do której należą dane.
Struktura
- Apache Hadoop jest ramą przetwarzania dużych zbiorów danych opartych na słynnym modelu programowania MapReduce odpowiedni do przetwarzania ogromnych zestawów danych, dystrybuowany na klastrze węzłów, równolegle. Jest to rozproszony system przetwarzania zaprojektowany do dystrybucji i przetwarzania dużych ilości danych w węzłach w klastrze. Z drugiej strony Cassandra to w pełni rozproszona baza danych NoSQL, która oferuje wyjątkowo solidny i ekspresyjny interfejs do modelowania i zapytania. To nie jest jak tradycyjne systemy bazy danych; W rzeczywistości przechowuje dane w pary wartości kluczowej. W przeciwieństwie do Hadoop, Cassandra jest wykorzystywana głównie do przetwarzania danych w czasie rzeczywistym.
Format danych
- Hadoop może pracować z dowolnymi danymi w różnych formatach, niezależnie od tego, czy jest to ustrukturyzowane, częściowo ustrukturyzowane, czy nie strukturalne, i cokolwiek możesz pomyśleć-obrazy, JSON, XML i tak dalej. Z drugiej strony Cassandra to rozproszony system zarządzania zaprojektowany do obsługi dużych ilości strukturalnych danych na serwerach towarowych. Co więcej, Cassandra nie obsługuje obrazów.
Architektura
- Hadoop podąża za architekturą niewolników głównych składających się z węzłów głównych i węzłów niewolników. Namemode to węzeł główny, a datanody to węzły niewolników. Zwykle demon datanode działa w każdym trybie niewolników i zarządza pamięcią podłączoną do każdego danych danych. HDFS można wdrożyć na szerokiej gamie maszyn z Java. Z drugiej strony Cassandra przechowuje dane na różnych węzłach z systemem rozproszonym peer-to-peer, ułatwiając obsługę i utrzymanie sklepa zdecentralizowanego niż sklep Master/Slave, ponieważ wszystkie węzły są takie same.
Hadoop vs. Cassandra: wykres porównawczy

Streszczenie
Hadoop jest kamieniem węgielnym rozwiązań Big Data, który oferuje najnowocześniejszą platformę do przechowywania i analizowania ogromnych ilości zestawów danych oraz ulepszania tradycyjnych systemów zarządzania relacyjnymi bazami danych. Apache Hadoop zapewnia odporne na uszkodzenia, rozproszone ramy do przechowywania i przetwarzania bardzo dużych zestawów danych w klastrach towarów. Cassandra to wiodąca baza danych NoSQL, która przyjmuje najlepsze postępy technologiczne z dokumentów Dynamo i Bigtable w celu obsługi dużych ilości strukturalnych danych na serwerach towarowych. Poza tym Cassandra doskonale nadaje się do szybkich transakcji online, podczas gdy Hadoop jest idealny do szybszego przechowywania i pobierania danych.