

Różnica między przetwarzaniem mgły a przetwarzaniem krawędzi

- 974
- 35
- Salwator Słowiński
Internet przedmiotów (IoT) został przygotowany jako kolejna wielka ewolucja po tym, jak Internet obiecuje zmienić nasze życie, łącząc fizyczne podmioty z Internetem w wszechobecny sposób, prowadząc do inteligentnego świata. Urządzenia IoT są wokół nas łączące urządzenia do noszenia, inteligentne samochody i inteligentne systemy domowe. W rzeczywistości badania sugerują, że wskaźnik, z jaką te urządzenia integrują się z naszym życiem, oczekuje się, że do 2020 r. Ponad 50 miliardów urządzeń zostanie połączonych z Internetem. Do tej pory podstawowym zastosowaniem Internetu jest łączenie maszyn obliczeniowych z maszynami podczas komunikowania się w formie stron internetowych. Ale IoT idzie o krok dalej.
Jednak, aby pomieścić tak ogromną liczbę podłączonych urządzeń i skutecznie zarządzać masowym napływem danych gromadzonych z każdego urządzenia, wymaga skalowalnej architektury. Ponadto większość urządzeń, które składają się na Internet przedmiotów, jest ograniczona zasobami; Zasoby takie jak przepustowość i magazyn i moc obliczeniowa są rzadkie. Takie wyzwania można złagodzić poprzez rozszerzenie funkcji przetwarzania w chmurze bliżej urządzeń IoT. Obliczanie mgły, znane również jako przetwarzanie krawędzi to potencjalne rozwiązanie, które rozszerza warstwę chmur, aby była bliżej rzeczy, które wytwarzają i konsumują dane. Ale jakie są te dwie technologie i jak różnią się od siebie?
Co to jest przetwarzanie mgły?
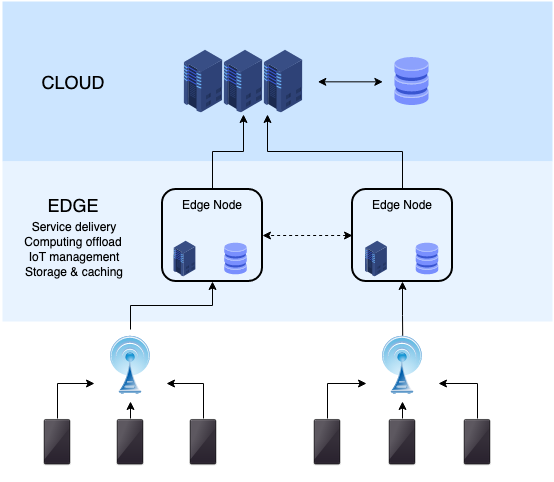
Termin przetwarzanie mgły zostało wymyślone przez Cisco i zdefiniowane jako rozszerzenie paradygmatu przetwarzania w chmurze z rdzenia sieci do krawędzi sieci. Przetwarzanie mgły to warstwa pośrednia, która rozszerza warstwę chmur, aby przybliżać urządzenia obliczeniowe, sieciowe i pamięciowe do nod końcowych w IoT. Urządzenia na krawędzi są nazywane węzłami mgażnymi i mogą być wdrażane w dowolnym miejscu z łącznością sieci. Jest to rozszerzenie przetwarzania w chmurze, a nie jego wymiany. Zmniejsza opóźnienie i pokonuje problemy bezpieczeństwa w wysyłaniu danych do chmury. Ze względu na ścisłą integrację z urządzeniami końcowymi, zwiększa ogólną wydajność systemu, poprawiając w ten sposób wydajność krytycznych systemów cyberprzestępczych.
Co to jest przetwarzanie krawędzi?
Chociaż główne cele przetwarzania krawędzi i obliczeń mgły są takie same - to znaczy obniżenie zatorów sieci i zmniejszenie opóźnienia end -to -end - jednak różnią się tym, jak przetwarzają i obsługują dane oraz gdzie umieszczane są inteligencja i moc obliczeniowa. Edge Computing to architektura, która korzysta z klientów użytkownika końcowego i jednej lub więcej urządzeń o prawie użytkownika Edge, aby popchnąć obiekt obliczeniowy w kierunku źródeł danych, e.G, czujniki, siłowniki i urządzenia mobilne. Popycha infrastrukturę obliczeniową do bliskości źródła danych, a złożoność obliczeniowa również wzrośnie. W takiej architekturze każde urządzenie z funkcjami obliczeniowymi, pamięciami i sieciami może służyć jako urządzenie o prawie użytkownika. Zazwyczaj zasoby krawędzi są konfigurowane w sposób ad hoc w celu poprawy ogólnej wydajności systemu.
Różnica między przetwarzaniem mgły a przetwarzaniem krawędzi
Pojęcie
- Chociaż główne cele przetwarzania krawędzi i obliczeń mgły są takie same - to znaczy obniżenie zatorów sieci i zmniejszenie opóźnienia end -to -end - jednak różnią się tym, jak przetwarzają i obsługują dane oraz gdzie umieszczane są inteligencja i moc obliczeniowa. Oba terminy są często używane zamiennie, ponieważ oba obejmują wprowadzenie inteligencji i mocy przetwarzania do tworzenia danych. Przetwarzanie mgły przesuwa inteligencję do poziomu sieci lokalnej architektury sieci, podczas przetwarzania danych w węźle mgły lub bramie IoT. Obliczanie krawędzi umieszcza inteligencję i moc bramki krawędziowej w urządzeniach, takich jak programowalne kontrolery automatyzacji.
Komunikacja danych
- W obliczeniach mgły komunikacja danych między urządzeniami generującymi dane a środowiskiem chmurowym wymaga szeregu kroków; Komunikacja jest najpierw kierowana do punktów we/wy PAC, po czym jest wysyłany do bramy protokołu, która przekształca dane w zrozumiały format. Dane są następnie przesyłane do węzła przeciwmgielnego sieci lokalnej, po czym dane są kierowane do chmury w celu przechowywania. Z drugiej strony w przetwarzaniu krawędzi komunikacja jest znacznie prostsza i istnieje potencjalnie mniejsze punkty awarii.
Architektura
- FOG Computing to zdecentralizowana infrastruktura obliczeniowa, która rozszerza przetwarzanie w chmurze i usługi na krawędź sieci w celu zbliżenia urządzeń do przetwarzania, sieci i pamięci masowej do nod końcowych w IOT. Celem jest poprawa wydajności i zmniejszenie ilości danych transportowanych do chmury w celu przetwarzania, analizy i przechowywania. Z drugiej strony przetwarzanie krawędzi jest starszym wyrażeniem poprzedzającym termin obliczania mgły. Jest to architektura, która korzysta z klientów użytkownika końcowego i jednej lub więcej urządzeń o prawie użytkownika Edge, aby wspierać obiekt obliczeniowy w kierunku źródeł danych, e.G, czujniki, siłowniki i urządzenia mobilne.
Przetwarzanie mgły vs. Obliczenie krawędzi: wykres porównawczy

Streszczenie
Krótko mówiąc, obliczenia mgły i obliczenia krawędzi są często używane jako oznaczające tę samą architekturę, a zatem terminy są uważane za wymienne; Można jednak dokonać subtelnego rozróżnienia. Chociaż oba oferują potencjalne rozwiązanie, które rozszerza warstwę chmur, aby była bliżej rzeczy, które produkują i konsumują dane, główną różnicą jest to, jak obsługują dane i gdzie umieszczane są inteligencja i moc obliczeniowa. W obliczeniach mgły inteligencja znajduje się w sieci lokalnej, gdzie jak w przetwarzaniu krawędzi, inteligencja i energia bramy Edge znajdują się w urządzeniach inteligentnych, takich jak programowalne kontrolery automatyzacji.