

Różnica między EMR a klejem

- 3946
- 479
- Patrycy Ziółkowski
AWS oferuje mnóstwo narzędzi i usług do przetwarzania ogromnych ilości danych. Przez lata AWS zbudował wiele usług analitycznych. W zależności od środowiska technicznego zawsze możesz wybrać jedno lub inne narzędzie do przetwarzania danych w oparciu o przepływy pracy maszynowej. Jeśli chodzi o obciążenia Analytics, Amazon EMR i AWS Glue to dwa popularne opcje przetwarzania danych na skalę. Przyglądamy się dwóch usług zarządzanych i staramy się zrozumieć kluczowe różnice między nimi. Więc zacznijmy.
Co to jest Amazon EMR?
Amazon Elastic MapReduce (EMR) to oparta na chmurze usługa zarządzana do przetwarzania i analizy dużych zbiorów danych szybko i opłacalnych. EMR to wiodąca w branży platforma dużych zbiorów danych, która upraszcza analizy dużych zbiorów danych za pomocą narzędzi takich jak Apache Spark, Apache Hadoop, Apache Hive, Apache HBase, Presto i tak dalej. Zaczęło się jako zarządzane środowisko dla aplikacji Apache Hadoop, ale przez lata dodawało wsparcie dla wielu innych projektów na AWS. EMR jest specjalnie zaprojektowany w celu zmniejszenia obciążenia konserwacyjnego poprzez zapewnienie zarówno mocy obliczeniowej, jak i infrastruktury na żądanie do analizy tak rozległych ilości danych. EMR bardzo wykorzystuje Amazon S3 do przechowywania zestawów danych do wyników przetwarzania i analizy oraz wykorzystuje Amazon EC2 do przetwarzania dużych zbiorów danych w klastrze serwerów wirtualnych. Jest elastyczny, dostosowywany i może działać zarówno w przypadku krótkich, jak i długich instancji. EMR jest głównym pretendentem do przetwarzania danych na dużą skalę.
Co to jest klej AWS?
AWS Glue to usługa pozbawiona serwera, w pełni zarządzana ekstrakcja, transformacja i ładowanie (ETL) świadczone przez Amazon w ramach AWS, aby pomóc czołgać się, odkrywać i organizować dane. Jest to usługa komputerowa, która zapewnia automatyczne wnioskowanie o schemacie dla twoich zbiorów danych strukturalnych i częściowo ustrukturyzowanych. Umożliwia wyodrębnienie danych i metadanych z wielu źródeł, takich jak bazy danych i budować katalog informacji, które można dalej wykorzystać do przekształcenia danych do wymaganego stanu docelowego. Rozumie twoje dane, sugeruje transformacje i generuje skrypty ETL, a ponadto uruchamia je w pełni zarządzany sposób w powładzie Python lub w pełni zarządzanym środowiskiem Spark bez serwera. W oparciu o transformacje zdefiniowane na danych, klej może automatycznie generować scenariusze Spark. Nie tylko możesz je dostosować, ale także wdrażać własne skrypty. Klej jest zbudowany na iskrze i jest zintegrowany z S3, RDS, Redshift i dowolnym magazynem danych JDBC.
Różnica między EMR a klejem
Narzędzie
- Amazon EMR to oparta na chmurze usługa zarządzana, która bardzo wykorzystuje Amazon S3 do przechowywania zestawów danych do przetwarzania i analizy, i wykorzystuje Amazon EC2 do przetwarzania dużych zbiorów danych w klastrze serwerów wirtualnych. Jest to w pełni zarządzane środowisko Hadoop, które zapewnia wsparcie dla wielu innych projektów na AWS, takich jak Apache Spark, Apache Hive, Apache Hbase, Presto i tak dalej. Z drugiej strony AWS Glue to narzędzie ETL bez serwera, które zapewnia automatyczne wnioskowanie schematu dla twoich zestawów danych strukturalnych i częściowo ustrukturyzowanych.
cennik
- Struktura cen Amazon EMR jest prosta i przewidywalna. Jesteś obciążony na drugiej podstawie, co oznacza, że płacisz za każdą sekundę, a co najmniej jeden minuta. Stawka godzinowa zależy od używanego typu instancji i zaczyna się od 0 USD.011 na godzinę i wzrasta do 0 USD.27 na godzinę. Opłaty są jak ceny EC2 dodane do kosztu przetwarzania danych. Ceny kleju AWS oparte są na DPU (jednostki przetwarzania danych), a drugi za Crawlers i ETL jest rozliczany. Zwykle kosztuje około 0 USD.44 na godzinę na DPU w przyrostach 1 sekundy, zaokrąglone do najbliższej sekundy.
Elastyczność i skalowalność
- Amazon EMR to w pełni zarządzana platforma klastra, która upraszcza konfigurację i zarządzanie klastrem komponentów Apache Hadoop i MapReduce. Zapewnia prosty sposób skalowania działających obciążeń w zależności od wymagań przetwarzania. Pozwala to zmienić rozmiar klastra, ponieważ wydaje się sprawny, a dodatkowo skonfiguruj jedną lub więcej grup instancji do przetwarzania. AWS Glue jest również elastyczny i łatwo skalowalny, ponieważ działa na w pełni zarządzanym, bez serwera środowiska. Autorzy wysoce skalowalne zadania ETL dla rozproszonego przetwarzania w skali środowiska Apache.
Przypadek użycia
- Amazon EMR to w pełni zarządzane środowisko, które zapewnia zarówno moc obliczeniową, jak i infrastrukturę na żądanie w celu szybkiego i efektywnego analizy danych danych. Upraszcza uruchamianie dużych danych, takich jak Apace Hadoop i Apache Spark na AWS do przetwarzania dużych zbiorów danych na skalę. Często jest to dobry zamiennik dla lokalnych migracji Hadoop. AWS Glue to platforma ETL bez serwera, która pomaga czołgać się, odkrywać i organizować posiadane dane oraz przygotować je do analizy. Jest idealny do nowych obciążeń.
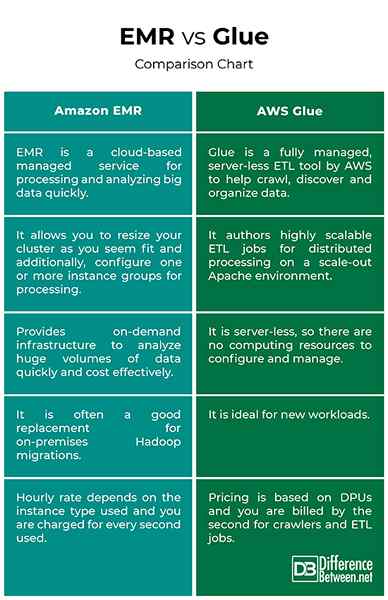
EMR vs. Klej: wykres porównawczy
Streszczenie
Krótko mówiąc, Amazon EMR to w pełni zarządzane środowisko, które zapewnia zarówno moc obliczeniową, jak i infrastrukturę na żądanie do szybkiego i efektywnego analizy danych danych. Tak więc, gdy masz dostępną całą infrastrukturę, EMR jest dla Ciebie najlepszą opcją. Z drugiej strony klej AWS jest przydatny, gdy masz elastyczne wymagania, a ponieważ jest on bez serwera, nie musisz konfigurować i zarządzać żadnymi zasobami komputerowymi. Klej po prostu pomaga czołgać się, odkrywać i organizować posiadane dane oraz przygotować je do analizy.