

Różnica między dyspersją a skośnością
- 2691
- 709
- Pelagia Radomski
Stopień zmian jest często wyrażany w kategoriach danych numerycznych w wyłącznym celu porównania teorii i analizy statystycznej. Zwykle obliczamy pojedynczą liczbę reprezentującą cały zestaw danych, który nazywa się „średnią”. Nie określa jednak żadnego konkretnego sposobu określenia składu serii. Z tego powodu wymagane są dodatkowe środki, aby oświecić nas w zakresie, w jaki sposób elementy różnią się od siebie lub wokół średniej. Aby zrozumieć bardzo szczegółowe pojęcia analizy ilościowej w statystykach, wykorzystujemy miary dyspersji i skośności. Dyspersja jest miarą zakresu rozmieszczenia wokół lokalizacji centralnej, podczas gdy skośność jest miarą asymetrii w rozkładu statystycznym.
Co to jest dyspersja?
W statystykach dyspersja jest miarą rozpowszechniania danych, co oznacza, że wskazują, w jaki sposób wartości w zestawie danych różnią się od siebie. Jest to zakres, w którym rozkład statystyczny rozkłada się wokół centralnego punktu. Określa głównie zmienność elementów danych danych wokół jego centralnego punktu. Mówiąc najprościej, mierzy stopień zmienności wokół wartości średniej. Miary dyspersji są ważne w celu ustalenia rozprzestrzeniania danych wokół miary lokalizacji. Na przykład wariancja jest standardową miarą dyspersji, która określa, w jaki sposób dane są rozmieszczone na temat średniej. Inne miary dyspersji to zakres i średnie odchylenie.
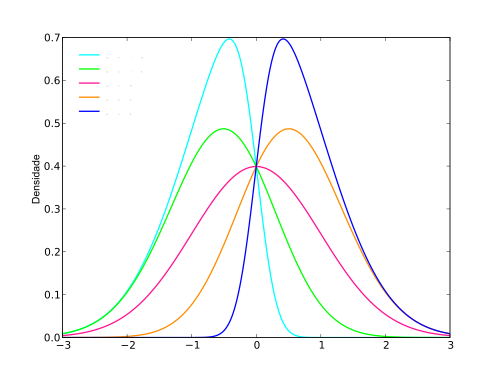
Co to jest skośność?
Skośność jest miarą asymetrii rozkładu w określonym punkcie. Rozkład może być lekko asymetryczny, silnie asymetryczny lub symetryczny. Miara asymetrii rozkładu jest obliczana za pomocą skośności. W przypadku pozytywnej skośności mówi się, że rozkład jest prawnie, a gdy skośność jest ujemna, mówi się, że rozkład jest lewym. Jeśli skośność wynosi zero, rozkład jest symetryczny. Skośność jest mierzona na podstawie średniej, mediany i trybu. Wartość skośności może być pozytywna, ujemna lub niezdefiniowana w zależności od tego, czy punkty danych są wypaczone w lewo, czy wypaczone po prawej stronie.
Różnica między dyspersją a skośnością
-
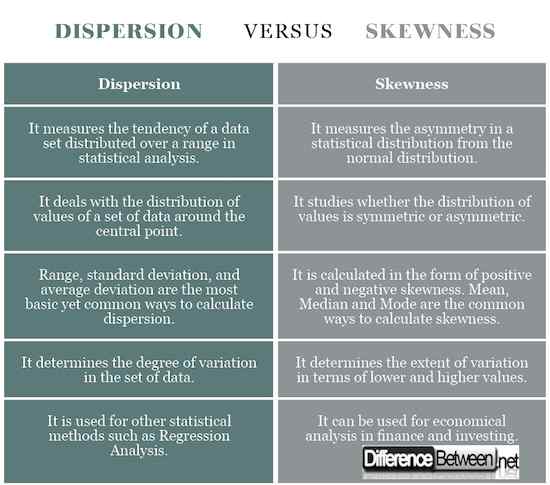
Definicja dyspersji vs. Skośność
W kategoriach statystycznych i teorii prawdopodobieństwa dyspersja jest wielkością zakresu wartości dla zmiennej losowej lub jej rozkładu prawdopodobieństwa. Opisuje zakres, do którego rozkład jest rozciągany lub rozkładany. Mówiąc najprościej, jest to środek do zbadania zmienności elementów. Z drugiej strony skośność jest miarą asymetrii w rozkładowi statystycznym losowej zmiennej na temat jej średniej. Wartość skośności może być zarówno pozytywna, jak i ujemna, a czasem niezdefiniowana. Mówiąc najprościej, mówi się, że rozkłady asymetryczne są wypaczone
-
Miary dyspersji vs. Skośność
Miary dyspersji oznaczają stopień, w jakim zmiany są zrównoważone od ich wartości centralnej. Mówiąc dokładniej, mierzy stopień zmienności wartości zmiennej wokół wartości średniej. Dyspersja wskazuje rozprzestrzenianie się danych. Miary skośności oznaczają, jak asymetryczny jest rozkład i określa, czy punkty danych są wypaczone w prawo, czy po lewej stronie. Jeśli mówi się, że rozkład jest wypaczony w lewo, wartość jest ujemna, a wartość dodatnia, jeśli rozkład jest wypaczony po prawej stronie.
-
Obliczanie dyspersji vs. Skośność
Dyspersja jest obliczana na podstawie pewnej średniej. Jest to obliczenie statystyczne, które mierzy stopień zmienności i istnieje wiele różnych sposobów obliczania dyspersji, ale oba najczęstsze to zakres i średnie odchylenie. Zakres to różnica między największymi i najmniejszymi wartościami w zestawie danych, podczas gdy średnie odchylenie jest średnią wartości bezwzględnych odchyleń wartości funkcjonalnych od punktu centralnego. Z drugiej strony skośność jest obliczana na podstawie średniej, mediany i trybu. Jeśli średnia jest większa niż tryb, masz dodatnie skoś, a w przypadku średniej jest mniejsza niż tryb, masz ujemne skoś. Dodatkowo rozkład ma zero skośne w przypadku rozkładu symetrycznego.
-
Zastosowania dyspersji vs. Skośność
Dyspersja jest używana głównie do opisania związku między zestawem danych i określenia stopnia zmienności wartości danych z ich średniej wartości. Dyspersja statystyczna może być stosowana do innych metod statystycznych, takich jak analiza regresji, która jest procesem stosowanym do zrozumienia związku między zmiennymi. Można go również wykorzystać do testowania niezawodności średniej. Z drugiej strony skośność dotyczy charakteru dystrybucji w zestawie danych. Jest to niezwykle pomocne, jeśli chodzi o analizę ekonomiczną w sektorze finansowym, która obejmuje duży zestaw danych, takich jak zwroty aktywów, ceny akcji itp.
Dyspersja vs. Skośność: wykres porównawczy
Podsumowanie dyspersji vs. Skośność
Oba są najczęstszymi terminami wykorzystywanymi w analizie statystycznej i teorii prawdopodobieństwa w celu scharakteryzowania zestawu danych obejmujących ogromną masę danych numerycznych. Dyspersja jest miarą obliczania zmienności danych lub zbadania zmian danych między sobą lub wokół jej średniej. Dotyczy głównie rozkładu wartości danych w zestawie wokół punktu centralnego. Można go mierzyć na wiele sposobów, z których najczęstsze są zakres i średnie odchylenie. Skośność służy do pomiaru asymetrii z rozkładu normalnego w zestawie danych, co oznacza stopień, w jakim rozkład jest równoważony wokół średniej.
- « Różnica między wynagrodzeniem rzeczywistym a wynagrodzeniem nominalnym
- Różnica między ścieżką bezwzględną i względną »