

Różnica między nadzorowanymi i bez nadzoru danych

- 2122
- 664
- Pan Antonina Ruciński
Wydobycie danych wykorzystuje mnóstwo metod obliczeniowych i algorytmów do pracy nad ekstrakcją wiedzy. Klasyfikacja jest prawdopodobnie najbardziej podstawową formą analizy danych. Powszechnym zadaniem w eksploracji danych jest zbadanie danych, w których klasyfikacja jest nieznana lub wystąpi w przyszłości, w celu przewidzenia, czym jest ta klasyfikacja lub będzie będzie. Podobnie dane, w których znana jest klasyfikacja, są wykorzystywane do opracowania reguł, które są następnie stosowane do danych, w których klasyfikacja jest nieznana. To powiedziawszy, techniki wydobywania danych występują w dwóch głównych formach: nadzorowanych i bez nadzoru. Nadzorowany jest techniką predykcyjną, podczas gdy bez nadzoru jest techniką opisową. Chociaż oba algorytmy są szeroko stosowane do wykonywania różnych zadań wydobywania danych, ważne jest, aby zrozumieć różnicę między nimi.
Co to jest nadzorowane wydobycie danych?
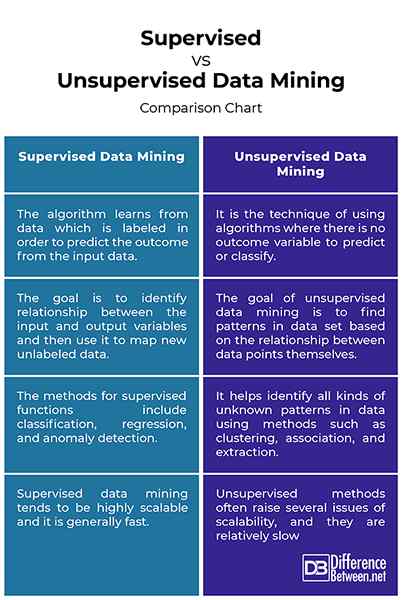
Nadzorowane wydobycie danych, jak sama nazwa wskazuje, odnosi się do algorytmów uczenia się, które są używane w klasyfikacji i prognozie. Algorytm nadzorowany uczy się na podstawie danych, które są oznaczone, a zadanie jest kontrolowane przez inżyniera wiedzy i projektanta systemu. Z nadzorowanymi danymi musieliśmy znać dane wejściowe odpowiadające znanym wyjściom, określone przez ekspertów domenowych. Zadanie eksploracji danych jest często określane jako nauka nadzorowana, ponieważ klasy są określane przed badaniem danych. Ta technika wykorzystuje funkcję celu (zmienną zależną) i zestaw elementów danych, które są zmiennymi niezależnymi. Nadzorowana technika próbuje zidentyfikować relacje między zmiennymi zależnymi i niezależnymi, zidentyfikować stopień korelacji dla każdego zestawu zmiennych i zbuduj model pokazujący sieć zależności. Model jest następnie stosowany do danych, dla których wartość docelowa jest nieznana.

Co to jest wydobycie danych bez nadzoru?
W przeciwieństwie do techniki nadzorowanej, eksploracja danych bez nadzoru nie ma z góry określonej funkcji celu, ani nie przewiduje wartości docelowej. Techniki bez nadzoru to te, w których nie ma zmiennej wyniku do przewidywania lub sklasyfikowania. Stąd nie ma uczenia się z przypadków, w których znana jest taka zmienna wyniku. Algorytm wymaga od użytkownika określenia liczby interwałów i/lub liczby punktów danych w dowolnym przedziale. Pomaga zidentyfikować wszelkiego rodzaju nieznane wzorce w danych. Model bez nadzoru jest również nazywany modelem opisowym, ponieważ szuka nieznanych wzorców w zestawie danych bez wcześniej określonych etykiet i bez minimalnego nadzoru ludzkiego. Metody uczenia się bez nadzoru obejmują metody grupowania, skojarzenia i ekstrakcji. Ten rodzaj techniki uczenia się jest używany, gdy określony cel nie jest dostępny lub gdy użytkownik stara się znaleźć ukryte relacje w danych.
Różnica między nadzorowanymi i bez nadzoru danych
Dane
- Nadzorowane uczenie się jest zadaniem eksploracji danych polegających na wykorzystaniu algorytmów do opracowania modelu znanych danych wejściowych i wyjściowych, co oznacza, że algorytm uczy się na podstawie danych oznaczonych w celu przewidzenia wyniku na podstawie danych wejściowych. Nadzorowana technika to po prostu uczenie się z zestawu danych szkoleniowych. Z drugiej strony uczenie się bez nadzoru jest techniką stosowania algorytmów, w których nie ma zmiennej wyniku do przewidywania lub klasyfikacji, co oznacza, że nie ma uczenia się z przypadków, w których taka zmienna wynikowa jest znana.
Bramka
- Nadzorowana technika próbuje zidentyfikować swobodne związki między zmiennymi zależnymi i niezależnymi, wyodrębnić stopień korelacji dla każdego zestawu zmiennych i opracować model pokazujący sieć zależności. Model jest następnie stosowany do danych, dla których wartość docelowa jest nieznana. Uczenie się bez nadzoru dąży do identyfikacji nieznanych wzorców w zestawie danych bez określonych etykiet i bez minimalnego nadzoru ludzkiego. Celem bez nadzoru technik wydobywania danych jest znalezienie wzorców w zestawie danych w oparciu o związek między samymi punktami danych.
metoda
- Modele nadzorowane są stosowane w klasyfikacji i prognozie, stąd nazywane modelem predykcyjnym, ponieważ uczą się na podstawie danych szkoleniowych, z których uczy się klasyfikacja lub algorytm prognozy. Po wyciągnięciu algorytmu na podstawie danych szkoleniowych jest on zastosowany do innej próbki danych, w których znany jest wynik. Metody obejmują następujące funkcje nadzorowane: klasyfikacja, regresja i wykrywanie anomalii. Bez nadzoru eksploracja danych pomaga zidentyfikować wszelkiego rodzaju nieznane wzorce w danych przy użyciu takich metod, jak klastrowanie, skojarzenie i ekstrakcja.
Skalowalność
- Skalowalność jest jednym z głównych problemów związanych z wydobywaniem dużych zestawów danych i nie jest praktyczne przeanalizowanie całego zestawu danych więcej niż raz. Nadzorowane wydobycie danych jest zwykle wysoce skalowalne, co oznacza, że może obsługiwać ogromne ilości danych w ramach czasowych, które nie rosną nieuzasadnione, i jest ogólnie szybki. Z drugiej strony metody uczenia się bez nadzoru często podnoszą kilka problemów, jeśli chodzi o skalowalność, jeśli nie jest używana jakaś równoległa ocena, i w przeciwieństwie do nauki nadzorowanej, jest stosunkowo powolna, ale może zbiegać się w kierunku wielu zestawów stanów rozwiązania.
Nadzorowany vs. Bez nadzoru eksploracja danych: wykres porównawczy
Streszczenie
Krótko mówiąc, nadzorowane wydobycie danych jest techniką predykcyjną, podczas gdy bez nadzoru eksploracja danych jest techniką opisową. Nadzorowane techniki są stosowane, gdy dostępny jest określony cel, a użytkownik stara się ustalić, w jaki sposób zmiany stanu danych wpływają na wynik. Z drugiej strony bez nadzoru eksploracja danych zaczyna się od czystej tablicy, co oznacza, że nie ma predefiniowanej funkcji celu, a użytkownik próbuje znaleźć nieznane wzorce lub ukryte relacje w danych. Celem bez nadzoru eksploracji danych jest znalezienie wzorców w zestawie danych w oparciu o związek między punktami danych.
- « Różnica między eksploracją danych a profilowaniem danych
- Różnica między przetwarzaniem partii a przetwarzaniem strumienia »