

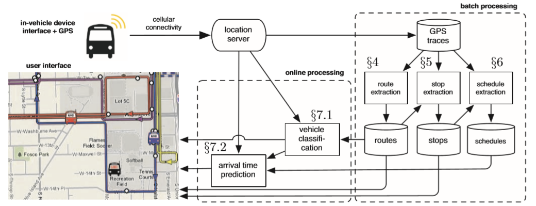
Różnica między przetwarzaniem partii a przetwarzaniem strumienia
- 2303
- 270
- Spirydion Kruk
Dane są nową walutą w dzisiejszej cyfrowej gospodarce. Wiele organizacji wykorzystuje technologie Big Data i chmurowe w celu ulepszenia tradycyjnej infrastruktury IT i wspierają kulturę i podejmowanie decyzji przy jednoczesnym modernizacji centrów danych. Jednak wirtualizacja i automatyzacja są tylko częścią przejścia do środowiska chmurowego. Podejścia do spełnienia rosnących wymagań biznesowych muszą zostać dostosowane do przedsiębiorstwa. Podczas gdy przetwarzanie w chmurze jest niczym innym jak rewolucyjną zmianą w technologiach branżowych i chmurowych jest kluczem do zapewnienia wyrafinowanej struktury zarządzania danymi, wyzwaniem jest przetwarzanie danych szybciej - przetwarzanie wsadowe lub przetwarzanie strumienia. Każdy ma swoje zalety i wady, ale wszystko sprowadza się do sprawy użycia firmy. Spójrzmy na dwa podejścia i dowiedzmy się, że różnice między nimi.
Co to jest przetwarzanie wsadowe?
Przetwarzanie wsadowe jest metodą przetwarzania dużych objętości danych w grupie lub partii w określonym przedziale czasu. Systemy wykonują serię programów, które przyjmują zestaw plików danych jako dane wejściowe, przetwarza dane i tworzą zestaw plików danych jako wyjście. Dobrym przykładem przetwarzania partii są systemy płac i rozlicze. Jest to przetwarzanie bloków danych, które zostały już przechowywane w określonym okresie czasu. Jest tak nazywany, ponieważ dane są gromadzone w partiach jako zestawy rekordów i przetwarzane jako jednostka. Wyjście to kolejna partia, którą można ponownie wykorzystać jako dane wejściowe w razie potrzeby. Prostota i wyrafinowanie systemu wsadowego pozwala również na równoległe przetwarzanie, e.G., Hadoop.
Co to jest przetwarzanie strumienia?
Przetwarzanie strumienia jest metodą stosowaną do zapytania ciągłego strumienia danych i szybkiego wykrywania warunków w ograniczonym czasie. Innymi słowy, przetwarzanie strumieniowe jest przetwarzaniem danych bezpośrednio, ponieważ są one wytwarzane lub odbierane. Systemy przetwarzania strumieni często karmią się działaniami, które występują w czasie rzeczywistym, takie jak komunikaty mediów społecznościowych, kliknięcia stron internetowych, transakcje e -commerce, odczyty czujników i tak dalej. Systemy te powinny mieć szybszy przetwarzanie niż szybkość danych przychodzących. Podstawową ideą przetwarzania strumienia jest to, że systemy powinny być długotrwałe, zajmując się ciągłym strumieniem danych. Aby uzyskać wartość z dużych zbiorów danych, dane muszą zostać przetworzone, gdy tylko się pojawią. Skuteczne przetwarzanie strumienia może rozwiązać szeroką gamę rzeczywistych problemów. Na przykład strumień można wykorzystać do wykrywania oszustw, podejmowania decyzji, uczenia się wzorców itp.
Różnica między przetwarzaniem partii a przetwarzaniem strumienia
Definicja
- Przetwarzanie wsadowe jest metodą przetwarzania dużych objętości danych w grupie lub partii w określonym czasie. Nazywa się to przetwarzaniem partii, ponieważ dane są gromadzone w partiach jako zestawy rekordów i przetwarzane jako jednostka. Wyjście to kolejna partia, która może być ponownie wykorzystana jako wejście, jeśli jest to wymagane. Z drugiej strony przetwarzanie strumienia jest metodą przetwarzania danych bezpośrednio w momencie ich tworzenia lub odbierania. Służy do zapytania ciągłego strumienia danych i szybkiego wykrywania warunków w ograniczonym czasie.
Model
- W przetwarzaniu wsadowym system wykonuje serię programów, które przyjmują zestaw plików danych jako dane wejściowe, przetwarza dane i tworzy zestaw plików danych jako wyjście. Komponent wejściowy jest odpowiedzialny za gromadzenie danych z wielu źródeł, zwykle baz danych, a komponent przetwarzania jest odpowiedzialny za wykonywanie obliczeń za pomocą tych danych wejściowych. Wreszcie komponent wyjściowy generuje wyniki zapisane z powrotem do baz danych. W przetwarzaniu strumienia system wykonuje przetwarzanie najnowszego zapisu danych, co oznacza, że systemy zasilają działanie, które występują w czasie rzeczywistym.
Przykład
- Najlepszym przykładem systemów przetwarzania wsadowego są systemy płac i rozlicze. Wiele rozproszonych platform programowych, takich jak MapReduce, Spark, Graphx i Htcondor, to systemy przetwarzania wsadowe. Przetwarzanie strumienia może być wykorzystywane jako rozwiązanie online do wykrywania oszustw i stosowane do aplikacji, które wymagają ciągłego wyjścia z danych przychodzących, takich jak giełdzie, komunikaty mediów społecznościowych, transakcje e -commerce, odczyty czujników itp. Platformy programowania dużych zbiorów danych, takie jak Storm, Spark Streaming i S4, to systemy przetwarzania strumienia.
Przetwarzanie wsadowe vs. Przetwarzanie strumienia: wykres porównawczy

Podsumowanie przetwarzania wsadowego vs. Przetwarzanie strumienia
Podczas gdy systemy przetwarzania wsadowe są znacznie mniej złożone i bardziej wyrafinowane w porównaniu z systemami przetwarzania strumieni, koszt systemów przetwarzania wsadowego może wydawać się mniej wykonalny dla niektórych firm i organizacji, które na początku nie mają drogiego sprzętu. Jednak systemy przetwarzania strumieni mogą być używane w aplikacjach, które wymagają ciągłego wyjścia z przychodzących danych w czasie rzeczywistym, takich jak aplikacje w mediach społecznościowych, giełdzie itp. Podczas gdy przetwarzanie strumieni działa najlepiej w przypadku użytku biznesowego, w których czas jest ograniczeniem, przetwarzanie wsadowe działa dobrze, gdy wszystkie powiązane zostały wstępnie przechowywane. Więc wszystko sprowadza się do sprawy użycia firmy.
- « Różnica między nadzorowanymi i bez nadzoru danych
- Różnica między płytą backningową a płytą główną »