

Różnica między adnotacją danych a znakowaniem
- 1710
- 282
- Pani — Jóźwiak
Od lat firmy inwestują mocno w uczenie maszynowe. W rzeczywistości uczenie maszynowe jest jednym z najbardziej aktywnych obszarów badawczych w dziedzinie sztucznej inteligencji (AI). Głównym celem badań w dziedzinie uczenia maszynowego jest tworzenie inteligentnych, świadomych maszyn lub komputerów zdolnych do odtworzenia ludzkich umiejętności poznawczych i zdobycie wiedzy samodzielnie. Tak więc zrozumienie człowieka wystarczająco dobrze, aby odtworzyć aspekty tego uczenia się w maszynach, jest godnym naukowym samym w sobie. Codziennie ludzie uczą komputery, aby rozwiązywać wiele nowych i ekscytujących problemów, takich jak gra na ulubionej liście odtwarzania, pokazanie wskazówek dotyczących najbliższej restauracji i tak dalej.
Ale wciąż jest tak wiele rzeczy, które komputery nie mogą zrobić, szczególnie w kontekście zrozumienia ludzkich zachowań. Metody statystyczne okazały się skutecznym środkiem do podejścia do tych problemów, ale techniki uczenia maszynowego działają lepiej, gdy algorytmy są wyposażone w wskazówki do tego, co jest istotne i znaczące w zestawie danych, a nie ogromne buły danych. W kontekście przetwarzania języka naturalnego wskaźniki te często mają formę adnotacji - sztuki etykietowania danych dostępnych w różnych formatach. Adnotacja danych i etykietowanie to dwa podstawowe elementy uczenia maszynowego, które pomagają maszynom rozpoznać obrazy, tekst i filmy.
Co to jest adnotacja danych?
Po prostu dostarczenie komputera z ogromnymi ilością danych i oczekiwanie, że nauka się mówić, nie wystarczy. Dane muszą zostać zebrane i przedstawione w taki sposób, aby komputer mógł łatwo rozpoznać wzorce i wnioski z danych. Zwykle odbywa się to poprzez dodanie odpowiednich metadanych do zestawu danych. Każdy znacznik metadanych używany do oznaczenia elementów zestawu danych nazywa się adnotacją nad wejściem. Tak więc w uczeniu maszynowym dane muszą być adnotowane lub po prostu powiedzieć, oznaczone, aby system mógł łatwo rozpoznać. Ale aby algorytmy mogły się skutecznie i skutecznie, adnotacja danych musi być dokładna i istotna dla zadania, którego zadaniem jest komputer. Mówiąc najprościej, adnotacja danych jest techniką etykietowania danych, aby maszyna mogła zrozumieć i zapamiętać dane wejściowe.
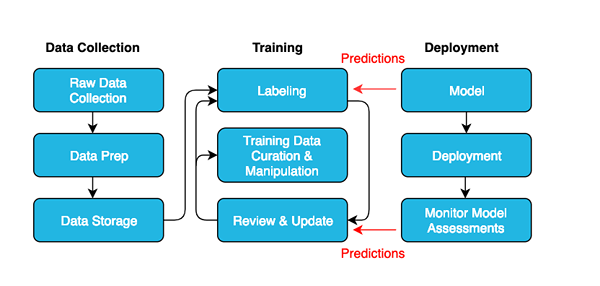
Co to jest etykietowanie danych?
Dane są dostępne w wielu różnych formach, takich jak tekst, obrazy, audio i wideo. Aby wzbogacić dane, aby maszyna mogła je rozpoznać za pomocą algorytmów uczenia maszynowego, dane muszą być oznaczone. Etykietowanie danych, jak sama nazwa wskazuje, to proces identyfikacji surowych danych, aby dołączyć znaczenie różnych rodzajów danych w celu wyszkolenia modelu uczenia maszynowego. Gdy dane są oznaczone, służy do szkolenia zaawansowanych algorytmów do rozpoznawania wzorców w przyszłości. Etykietowanie polega zasadniczo na oznaczanie danych lub dodawanie metadanych, aby było bardziej znaczące i pouczające, aby maszyny mogły je zrozumieć i uczyć się z tego. Na przykład etykieta może wskazywać, że obraz zawiera osobę lub zwierzę lub plik audio jest w jakim języku, lub w celu ustalenia rodzaju działania wykonanego w filmie.
Różnica między adnotacją danych a znakowaniem
Oznaczający
- Zarówno etykietowanie danych, jak i adnotacja są często używanymi wymiennie, aby przedstawić proces oznaczania lub oznaczania danych dostępnych w wielu różnych formatach. Adnotacja danych jest w zasadzie techniką oznaczania danych, aby maszyna mogła zrozumieć i zapamiętać dane wejściowe za pomocą algorytmów uczenia maszynowego. Etykietowanie danych, zwane także tagowaniem danych, oznacza dołączenie pewnego znaczenia do różnych rodzajów danych w celu wyszkolenia modelu uczenia maszynowego. Etykietowanie identyfikuje pojedynczy byt z zestawu danych.
Zamiar
- Etykietowanie jest kamieniem węgielnym nadzorowanego uczenia maszynowego, a różne branże nadal polegają w dużej mierze na ręcznej adnotowaniu i etykietowaniu ich danych. Etykiety służą do identyfikacji funkcji danych dla algorytmów NLP, podczas gdy adnotacja danych może być używana do modeli percepcji opartych na wizualnych. Etykietowanie jest bardziej skomplikowane niż adnotacja. Adnotacja pomaga rozpoznać odpowiednie dane za pośrednictwem Computer Vision, podczas gdy etykietowanie jest wykorzystywane do szkolenia zaawansowanych algorytmów do rozpoznawania wzorców w przyszłości. Oba procesy należy wykonać z absolutną dokładnością, aby upewnić się, że coś znaczącego wyjdzie z danych, aby opracować model AI oparty na NLP.
Aplikacje
- Adnotacja danych jest podstawowym elementem tworzenia danych szkoleniowych dla wizji komputerowej. Dane z adnotacjami są wymagane do szkolenia algorytmów uczenia maszynowego, aby zobaczyć świat, tak jak my, ludzie. Chodzi o to, aby maszyny były wystarczająco inteligentne, aby uczyć się, działać i zachowywać się jak ludzie, ale skąd pochodzi ta inteligencja? Odpowiedź brzmi: wiele i dużo. Adnotacja to proces stosowany w nadzorowanym uczeniu maszynowym do szkolenia zestawów danych, aby pomóc maszynom zrozumieć i rozpoznać dane wejściowe i działać odpowiednio. Etykietowanie służy do identyfikacji kluczowych funkcji obecnych w danych przy jednoczesnym minimalizowaniu zaangażowania człowieka. Przypadki użycia w świecie rzeczywistym obejmują NLP, przetwarzanie audio i wideo, wizje komputerowe itp.
Adnotacja danych vs. Etykietowanie danych: wykres porównawczy

Streszczenie
Adnotacja to proces stosowany w nadzorowanym uczeniu maszynowym do szkolenia zestawów danych, aby pomóc maszynom zrozumieć i rozpoznać dane wejściowe i działać odpowiednio. Etykietowanie służy do identyfikacji kluczowych funkcji obecnych w danych przy jednoczesnym minimalizowaniu zaangażowania człowieka. Etykietowanie jest kamieniem węgielnym nadzorowanego uczenia maszynowego, a różne branże nadal polegają w dużej mierze na ręcznej adnotowaniu i etykietowaniu ich danych. Ponieważ słabe etykietowanie może prowadzić do zagrożonej sztucznej inteligencji, etykietowanie lub adnotacja musi być wykonana dokładnie, aby mogły być używane do aplikacji AI.