

Różnica między klastrowaniem a klasyfikacją
- 4675
- 1301
- Prokop Cebula
Techniki grupowania i klasyfikacji są stosowane w uczeniu maszynowym, wyszukiwaniu informacji, badaniu obrazu i powiązanych zadaniach.
Te dwie strategie to dwa główne podziały procesów wydobywania danych. W świecie analizy danych są one niezbędne w zarządzaniu algorytmami. W szczególności oba te procesy dzielą dane na zestawy. To zadanie jest bardzo istotne w dzisiejszym wieku informacyjnym, ponieważ ogromny wzrost danych w połączeniu z rozwojem musi być trafnie ułatwiony.
W szczególności klastrowanie i klasyfikacja pomaga w rozwiązywaniu problemów globalnych, takich jak przestępczość, ubóstwo i choroby za pośrednictwem nauki o danych.
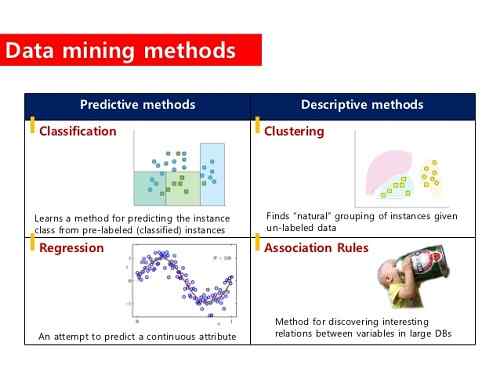
Co się skupia?
Zasadniczo grupowanie obejmuje grupowanie danych w odniesieniu do ich podobieństw. Dotyczy przede wszystkim pomiarów odległości i algorytmów grupowania, które obliczają różnicę między danymi i systematycznie dzielą.
Na przykład uczniowie o podobnych stylach uczenia się są zgrupowani i są nauczani osobno od tych z różnymi podejściami do uczenia się. W eksploracji danych klastrowanie jest najczęściej określane jako „technika uczenia się bez nadzoru”, ponieważ grupowanie opiera się na charakterystyce naturalnej lub nieodłącznej.
Jest stosowany w kilku dziedzinach naukowych, takich jak technologia informacyjna, biologia, kryminologia i medycyna.
Charakterystyka grupowania:
- Brak dokładnej definicji
Klastrowanie nie ma precyzyjnej definicji, dlatego istnieją różne algorytmy klastrowania lub modele klastrów. Z grubsza mówiąc, dwa rodzaje grupowania są twarde i miękkie. Hard Clustering dotyczy etykietowania obiektu jako po prostu należącego do klastra, czy nie. W przeciwieństwie do tego, miękkie grupowanie lub rozmyte grupowanie określa stopień, w jaki sposób coś należy do określonej grupy.
- Trudne do oceny
Walidacja lub ocena wyników analizy klastrowania jest często trudna do ustalenia ze względu na jego nieodłączną niedokładność.
- Bez nadzoru
Ponieważ jest to strategia uczenia się bez nadzoru, analiza opiera się jedynie na bieżących cechach; Zatem nie jest wymagane rygorystyczne regulacje.
Co to jest klasyfikacja?
Klasyfikacja pociąga za sobą przypisanie etykiet do istniejących sytuacji lub klas; Stąd termin „klasyfikacja”. Na przykład uczniowie wykazujący pewne cechy uczenia się są klasyfikowani jako uczniowie wizualne.
Klasyfikacja jest również znana jako „nadzorowana technik uczenia się”, w której maszyny uczą się na podstawie już oznaczonych lub sklasyfikowanych danych. Ma bardzo zastosowanie do rozpoznawania wzorców, statystyki i biometrii.
Charakterystyka klasyfikacji
- Wykorzystuje „klasyfikator”
Aby przeanalizować dane, klasyfikator jest zdefiniowanym algorytmem, który konkretnie mapuje informacje do określonej klasy. Na przykład algorytm klasyfikacji wyszkoliłby model w celu ustalenia, czy określona komórka jest złośliwa czy łagodna.
- Oceniane za pomocą wspólnych wskaźników
Jakość analizy klasyfikacji jest często oceniana za pomocą precyzji i wycofania, które są popularnymi procedurami metrycznymi. Klasyfikator jest oceniany pod kątem jego dokładności i wrażliwości w identyfikacji wyników.
- Nadzorowany
Klasyfikacja jest nadzorowaną techniką uczenia się, ponieważ przypisuje wcześniej określone tożsamości oparte na porównywalnych cechach. Oddała funkcję z etykietowanego zestawu treningowego.
Różnice między grupowaniem i klasyfikacją
- Nadzór
Główna różnica polega na tym, że klastrowanie nie jest nadzorowane i jest uważane za „samo-uczenie się”, podczas gdy klasyfikacja jest nadzorowana, ponieważ zależy od predefiniowanych etykiet.
- Korzystanie z zestawu treningowego
Klastrowanie nie wykorzystuje wzrośnie zestawów szkoleniowych, które są grupami instancji zastosowanych do generowania grup, a klasyfikacja niezbędna potrzebuje zestawów szkoleniowych w celu zidentyfikowania podobnych cech.
- Etykietowanie
Klastrowanie działa z nieznakowanymi danymi, ponieważ nie wymaga szkolenia. Z drugiej strony, klasyfikacja dotyczy zarówno danych nieznakowanych, jak i oznaczonych w swoich procesach.
- Bramka
Grupy grupowe obiekty w celu zawężenia relacji, a także poznanie nowych informacji z ukrytych wzorców, podczas gdy klasyfikacja ma na celu ustalenie, do której jawnej grupy należy określić określony obiekt.
- Szczegóły
Chociaż klasyfikacja nie określa, czego należy się nauczyć, grupowanie określa wymaganą poprawę, ponieważ wskazuje różnice, biorąc pod uwagę podobieństwa między danymi.
- Fazy
Ogólnie rzecz biorąc, klastrowanie składa się tylko z jednego fazy (grupowanie), podczas gdy klasyfikacja ma dwa etapy, szkolenie (model uczy się z zestawu danych treningowych) i testowanie (przewiduje się klasę docelową).
- Warunki brzegowe
Określenie warunków brzegowych jest bardzo ważne w procesie klasyfikacji w porównaniu z grupowaniem. Na przykład potrzebna jest znajomość procentowego zakresu „niskiego” w porównaniu z „umiarkowanym” i „wysokim” przy ustanowieniu klasyfikacji.
- Prognoza
W porównaniu z klastrowaniem klasyfikacja jest bardziej zaangażowana w prognozę, ponieważ szczególnie ma na celu klasę docelową tożsamości. Na przykład można to zastosować w „wykryciu kluczowych punktów twarzy”, ponieważ można go użyć do przewidywania, czy dany świadek kłamie, czy nie.
- Złożoność
Ponieważ klasyfikacja składa się z większej liczby etapów, zajmuje się prognozą i obejmuje stopnie lub poziomy, jej „charakter jest bardziej skomplikowany w porównaniu z grupą, co dotyczy grupowania podobnych atrybutów.
- Liczba prawdopodobnych algorytmów
Algorytmy grupowania są głównie liniowe i nieliniowe, podczas gdy klasyfikacja składa się z bardziej algorytmicznych narzędzi, takich jak klasyfikatory liniowe, sieci neuronowe, szacowanie jądra, drzewa decyzyjne i maszyny wektorowe wsparcia.
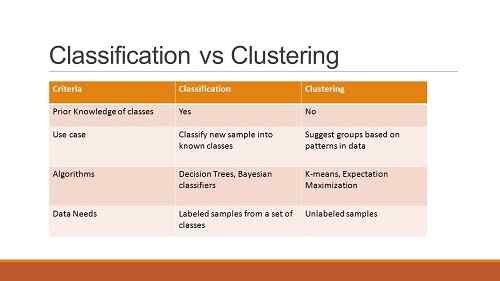
Klastrowanie vs klasyfikacja: Tabela porównująca różnicę między grupowaniem a klasyfikacją
| Grupowanie | Klasyfikacja |
| Dane bez nadzoru | Dane nadzorowane |
| Nie ceni zestawów treningowych | Czy bardzo cenią zestawy szkoleniowe |
| Działa wyłącznie z nieznakowanymi danymi | Obejmuje zarówno nieznakowane, jak i oznaczone dane |
| Ma na celu identyfikację podobieństw między danymi | Ma na celu sprawdzenie, gdzie należy do punktu odniesienia |
| Określa wymaganą zmianę | Nie określa wymaganej poprawy |
| Ma jedną fazę | Ma dwie fazy |
| Określenie warunków brzegowych nie jest najważniejsze | Zidentyfikowanie warunków brzegowych jest niezbędne do wykonywania faz |
| Zasadniczo nie zajmuje się prognozą | Dotyczy prognoz |
| Głównie wykorzystuje dwa algorytmy | Ma wiele prawdopodobnych algorytmów do użycia |
| Proces jest mniej złożony | Proces jest bardziej złożony |
Podsumowanie klastrowania i klasyfikacji
- Zarówno analizy klastrowania, jak i klasyfikujące są wysoce stosowane w procesach wydobywania danych.
- Techniki te są stosowane w niezliczonych naukach, które są niezbędne w rozwiązywaniu problemów globalnych.
- Przeważnie klastrowanie dotyczy danych bez nadzoru; Zatem nieoznaczony, podczas gdy klasyfikacja działa z nadzorowanymi danymi; w ten sposób oznaczone. Jest to jeden z głównych powodów, dla których grupowanie nie wymaga zestawów treningowych podczas klasyfikacji.
- Istnieje więcej algorytmów związanych z klasyfikacją w porównaniu z grupowaniem.
- Klastrowanie ma na celu sprawdzenie, w jaki sposób dane są podobne lub odmienne między sobą, podczas gdy klasyfikacja koncentruje się na określeniu „klas” lub grup danych. To sprawia, że proces grupowania bardziej koncentruje się na warunkach brzegowych, a analiza klasyfikacji jest bardziej skomplikowana w tym sensie, że obejmuje więcej etapów.