

Różnica między Big Data a Hadoop

- 3526
- 163
- Maksym Cieślik
Relacja między dużymi zbiorami danych a Hadoop jest jednym z ważnych przedmiotów zainteresowania wśród początkujących. A rozróżnienie między tymi dwoma powiązanymi koncepcjami jest raczej fascynujące. Big Data jest cennym zasobem, który bez jego obsługi nie ma szczególnego użytku. Tak więc Hadoop jest przewodnikiem, który wyświetla najlepszą wartość z zasobu. Przyjrzyjmy się na tych dwóch, a następnie różnice między nimi.
Co to jest duże zbiory danych?
W dzisiejszym cyfrowym świecie jesteśmy otoczeni większością danych. Wystarczy powiedzieć, że dane są wszędzie. Szybka ewolucja Internetu i Internetu urządzeń (IoT) oraz ciągłe wykorzystanie mediów elektronicznych doprowadziły do narodzin e-commerce i mediów społecznościowych. W rezultacie wygenerowano ogromną ilość danych, a w rzeczywistości nadal generuje się codziennie. Jednak dane nie są przydatne, chyba że masz niezbędny zestaw umiejętności do ich analizy. Dane w obecnej formie to surowe dane, z których większość to treść generowana przez użytkownika, która należy analizować i przechowywać. Dane są generowane z wielu źródeł od mediów społecznościowych po systemy wbudowane/sensoryczne, dzienniki maszyn, witryny e-commerce itp. Przetwarzanie tak szalonej ilości danych jest trudne. Big Data to parasol, który odnosi się do wielu sposobów systematycznego zarządzania danych i przetwarzania na tak dużą skalę. Big Data odnosi się do dużych, złożonych zestawów danych, które są zbyt skomplikowane, aby je analizować przez tradycyjne aplikacje do przetwarzania danych.
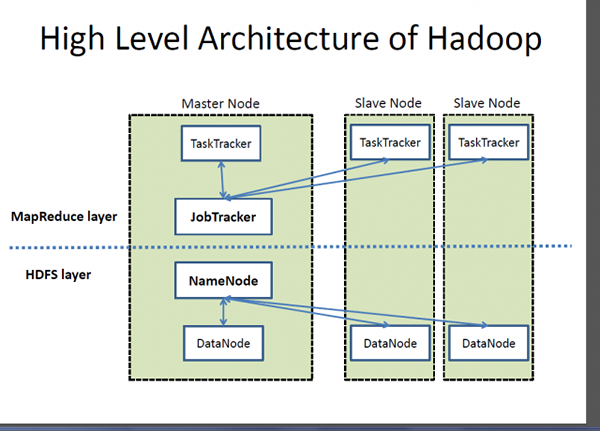
Co to jest hadoop?
Jeśli Big Data jest wysoce cennym zasobem, Hadoop jest programem lub narzędziem do wydobycia najlepszej wartości z tego zasobu. Hadoop to program narzędzi oprogramowania typu open source opracowany w celu rozwiązania problemu przechowywania i przetwarzania dużych, złożonych zestawów danych. Apache Hadoop jest prawdopodobnie jednym z najbardziej popularnych i powszechnie używanych ram oprogramowania używanych do przechowywania i przetwarzania dużych zbiorów danych. Jest to uproszczony model programowania, który umożliwia wygodne pisanie i sprawdzanie systemów rozproszonych oraz jego automatyczne, ekonomiczne dystrybucję wiedzy w towarach serwerów klastrowych. To, co wyróżnia Hadoop, jest jego zdolność do skalowania z jednego serwera do tysięcy maszyn do serwera towarowego. Mówiąc najprościej, Apache Hadoop jest de facto programem oprogramowania do przechowywania i przetwarzania ogromnej ilości danych, co często nazywa się Big Data. Dwa kluczowe elementy ekosystemu Hadoop to system plików rozproszony Hadoop (HDFS) i model programowania MapReduce.
Różnica między Big Data a Hadoop
Podstawy
- Big Data i Hadoop są dwoma najbardziej znanymi terminami ściśle ze sobą powiązanymi w sposób, który bez Hadoopa Big Data nie miałby znaczenia ani wartości. Pomyśl o dużych zbiorach danych jako o aktywach o głębokiej wartości, ale aby wydobyć pewną wartość z tego zasobu, potrzebujesz sposobu. Tak więc Apache Hadoop to program narzędziowy, który ma na celu pozyskanie najlepszej wartości z dużych zbiorów danych. Big Data odnosi się do dużych, złożonych zestawów danych, które są zbyt skomplikowane, aby je analizować przez tradycyjne aplikacje do przetwarzania danych. Apache Hadoop to struktura oprogramowania używana do obsługi problemu przechowywania i przetwarzania dużych, złożonych zestawów danych.
Pojęcie
- Dane w jego surowej formie nie są użyteczne i bardzo trudne do pracy, chyba że przekonwertujesz ten surowy encję o nazwie dane na informacje. Jesteśmy otoczeni mnóstwem danych, które widzimy i wykorzystujemy w tej erze cyfrowej. Na przykład mamy tyle treści na stronach i aplikacjach w mediach społecznościowych, takich jak Twitter, Instagram, YouTube itp. Tak więc Big Data odnosi się do tych ogromnych ilości danych ustrukturyzowanych, jak i nieustrukturyzowanych oraz informacji, które możemy uzyskać z tych danych, takich jak wzorce, trendy lub cokolwiek, co pomogłyby ułatwić te dane w pracy. Hadoop to rozproszone framework oprogramowania, który obsługuje przechowywanie i przetwarzanie tych dużych zestawów danych w towarach klastrowych serwerów.
Bramka
- Dane w obecnej formie to surowe dane, z których większość to treść generowana przez użytkownika, która należy analizować i przechowywać. Zestawy danych rosną w wykładniczym tempie i wychodzą spod kontroli. Musimy zatem sposoby obsługi wszystkich tych ustrukturyzowanych i nieustrukturyzowanych danych i potrzebujemy prostego modelu programowania, który zapewni odpowiednie rozwiązania światu Big Data. Wymaga to modelu obliczeniowego na dużą skalę, w przeciwieństwie do tradycyjnych modeli obliczeniowych. Apache Hadoop to system rozproszony, który umożliwia rozpowszechnianie obliczeń na kilku maszynach zamiast używania pojedynczego komputera. Został zaprojektowany do rozpowszechniania i przetwarzania ogromnej ilości danych w węzłach w klastrze.
Big Data vs. Hadoop: wykres porównawczy
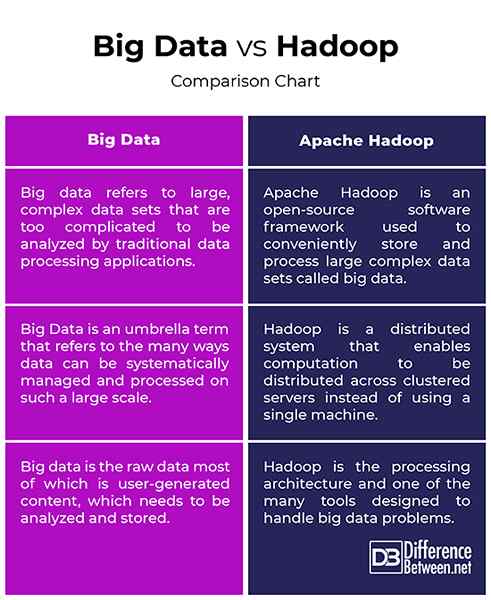
Podsumowanie dużych zbiorów danych vs. Hadoop
Big Data to wysoce cenny zasób, który nie ma przydatności, chyba że znajdziemy sposoby pracy. Aplikacje w mediach społecznościowych, takie jak Twitter, Facebook, Instagram, YouTube itp. to rzeczywiste przykłady dużych zbiorów danych, które stanowią pewne wyzwania dla technologii, których używamy w dzisiejszych czasach. Te szybko rosnące dane o nieustrukturyzowanej zawartości są powszechnie określane jako Big Data. Ale dane w swojej surowej formie są bardzo trudne do pracy. Potrzebujemy sposobów na pozyskiwanie, przechowywanie, przetwarzanie i analizę tych danych, abyśmy mogli uzyskać z nich coś użytecznego, takiego jak pewien wzór lub trend. Hadoop jest tym narzędziem, które pomaga przechowywać i przetwarzać te złożone zestawy danych, które są zbyt duże, aby je obsłużyć za pomocą tradycyjnych technik i narzędzi obliczeniowych.