

Różnica między tokenizacją a maskowaniem
- 1386
- 351
- Spirydion Kruk
Jednym z największych obaw organizacji zajmujących się bankowością, ubezpieczeniem, detalicznie i produkcją jest prywatność danych, ponieważ firmy te zbierają duże dane o swoich klientach. I to nie są tylko dane, ale poufne, prywatne dane, które po prawidłowym wydobyciu dają wiele informacji na temat swoich klientów. Firmy wykorzystują te dane o klientach do podejmowania lepszych decyzji biznesowych, takich jak świadczenie usług o wartości dodanej dla klientów, co może skutkować dodatkowym przychodem i zwiększonym zyskiem. Wszystkie te wrażliwe dane, które muszą być chronione przez cały czas, ponieważ można je wykorzystać, jeśli wpadną w niewłaściwe ręce. To prowadzi nas do naszego tematu zainteresowania - prywatność danych. Jeśli chodzi o prywatność danych, dostępne są dwie powszechne, ale skuteczne metody ochrony wrażliwych danych - tokenizacja i maskowanie.
Co to jest tokenizacja?
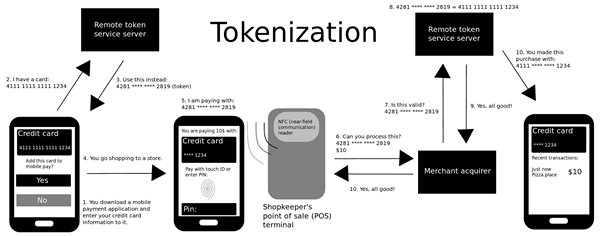
Tokenizacja jest prawdopodobnie jedną z najstarszych technik używanych do zapewnienia bezpieczeństwa danych. Ponieważ większość danych i informacji jest online, takie jak portfele cyfrowe, konieczne jest chronienie danych przed wścibskimi oczami. Tokenizacja jest metodą zastąpienia oryginalnych wrażliwych danych niewrażliwymi symbolami zastępczymi, zwanymi tokenami. Chodzi o to, aby całkowicie zastąpić oryginalne dane zastępcą, który nie ma związku z oryginalnymi danymi. Technika tokenizacji jest szeroko stosowana w branży kart kredytowych, ale z czasem jest przyjmowana również przez inne domeny. To, co tak naprawdę robi, to zachowanie poufnych danych, takich jak numer karty kredytowej w czymś o nazwie sklepienie token, które zasadniczo znajduje się poza systemem w bezpiecznej lokalizacji. Chociaż token jest powiązany z Twoimi bezpiecznymi danymi, jest całkowicie bezużyteczny gdzie indziej. Jest to jedynie odniesienie do twoich wrażliwych danych i to wszystko.

Co to jest maskowanie?
Maskowanie to kolejne skuteczne rozwiązanie w zakresie ochrony prywatności danych. Jak wiecie, ilość danych, którymi organizacje muszą zarządzać, rośnie w niespotykanym tempie. A ochrona prywatności danych staje się nowym wyzwaniem. Maskowanie jest techniką stosowaną do ochrony prywatności danych odczulonych dla środowiska produkcyjnego i testowego. Jest to proces zasłaniania, anonimowania lub tłumienia danych poprzez zastąpienie poufnych danych losowymi znakami lub po prostu wszelkimi niewrażliwymi danymi. Zasadniczo chroni twoje wrażliwe dane przed narażeniem na osoby, które nie są upoważnione do przeglądania lub dostępu. Maskowanie umożliwia programistom dostęp do bezpiecznych baz danych bez ryzyka narażenia na poufne informacje. Istnieje kilka technik stosowanych do maskowania danych, takich jak podstawienie, scraming lub usunięcie. Maskowanie jest często wykorzystywane do ochrony numerów kart kredytowych i innych poufnych informacji finansowych.
Różnica między tokenizacją a maskowaniem
Technika
- Podczas gdy zarówno tokenizacja, jak i maskowanie są świetnymi technikami stosowanymi do ochrony wrażliwych danych, tokenizacja jest głównie stosowana do ochrony danych w spoczynku, podczas gdy maskowanie jest używane do ochrony używanych danych. Tokenizacja jest techniką zastąpienia oryginalnych danych niewrażliwymi symbolami zastępczymi, zwanymi tokenami. Token nie ma znaczenia poza systemem, który je tworzy i łączy z innymi danymi. Idea maskowania danych jest podobna, ale jest zasadniczo określana jako trwałe tokenizacja. Maskowanie ukrywa oryginalne wrażliwe dane, zastępując je losowymi znakami.
Proces
- Tokenizacja ma wartość, taka jak numer karty kredytowej klienta i zastępuje ją serią losowo wygenerowanych liczb o nazwie tokeny. W tym miejscu nie możesz wrócić do pierwotnej wartości, ponieważ wygodnie siedzi poza systemem w bezpiecznej lokalizacji. Chodzi o to, aby utworzyć wartość zastępczą, którą można dopasować do oryginalnego ciągu za pomocą bazy danych. W przeciwieństwie do tokenizacji, maskowanie nie można odwrócić znaczenia po losowaniu danych przy użyciu procesu maskowania, nie można go odwrócić z powrotem do pierwotnego stanu.
Przypadków użycia
- Najczęstszym zastosowaniem tokenizacji jest ochrona wrażliwych lub osobowych informacji, takich jak numery kart kredytowych, numery ubezpieczenia społecznego, numery kont, adresy e -mail, numery telefonów, numery paszportowe, numer prawa jazdy i tak dalej. Maskowanie danych w praktyce jest stosowane głównie w dwóch obszarach aplikacji, kopii zapasowych bazy danych i eksploracji danych. Maskowanie może być idealne, gdy trzeba wyśmiewać dane bez widzenia oryginalnych danych. Może to być korzystne do testowania lub profilowania. Istnieje kilka technik stosowanych do maskowania danych, takich jak podstawienie, wspinanie się, tasowanie, szyfrowanie lub usuwanie.
Tokenizacja vs. Maskowanie: wykres porównawczy

Streszczenie
Oba są powszechnie stosowane techniki stosowane w ramach kompleksowej strategii prywatności danych, ale po prostu wiedza o nich nie jest wystarczająca, aby budować skuteczną architekturę bezpieczeństwa. Jako jedna z podstawowych strategii prywatności danych, tokenizacja jest jedną z najczęstszych metod wykorzystywanych do rozpoznania poufnych informacji poprzez zastąpienie oryginalnych danych niewrażliwą wartością zwaną tokenem. Ten token jest jedynie odniesieniem do oryginalnych danych, ale nie ma własnej wartości. Wygląda tylko jak oryginalne dane i jest odwzorowane z powrotem na oryginalne dane za pomocą bazy danych. Idea maskowania danych jest podobna, ale różnica polega na tym, jak działają. Maskowanie zasadniczo tłumi dane, zastępując je losowymi znakami lub po prostu wszelkimi niewrażliwymi danymi, i można to zrobić za pomocą jednego z wielu sposobów.