

Różnica między wydobywaniem tekstu a wydobyciem danych
- 2551
- 155
- Pani — Jóźwiak
Żyjemy w erze cyfrowej, w której codziennie gromadzone są ogromne ilości danych. Terabajty lub petabajty danych są generowane codziennie. Ale dane w jego surowej formie nie są przydatne, więc analiza takich danych jest ważna. Wydobycie danych pomaga analizować takie ogromne ilości danych, dostarczając narzędzia do odkrywania wiedzy na podstawie danych. Wydobywanie tekstu jest subtypem eksploracji danych, które zamienia niewykorzystane dane tekstowe w cenne zasoby.
Co to jest wydobycie danych?
Podobnie jak w przypadku wyodrębnienia złota z Ziemi w czystej formie poprzez wydobycie, eksploracja danych jest sortowaniem i ekstrakcją znaczących informacji lub danych z dużych zestawów danych. Wydobycie danych zwykle obejmuje identyfikację trendów lub wzorców w danych, które zwykle wykraczają poza proste procedury analizy za pomocą algorytmów oprogramowania i metod statystycznych. Znany również jako odkrycie wiedzy w danych (KDD), wydobycie danych ma na celu uzyskanie cennych informacji z danych, aby pomóc w odpowiedzi na pytania biznesowe i przewidzieć przyszłe trendy i zachowania.
Można to przeglądać w wyniku naturalnej ewolucji technologii informatycznych. Mówiąc najprościej, wydobycie danych to wydobycie wiedzy na podstawie danych. Źródła danych mogą obejmować bazy danych, hurtowni danych, WWW lub inne repozytoria informacyjne. Można go zastosować do zasadniczo wszystkich form danych, w tym danych przestrzennych, danych wykresowych lub sieciowych, strumieni danych, danych uporządkowanych/sekwencji oraz danych tekstowych.
Co to jest wydobycie tekstu?
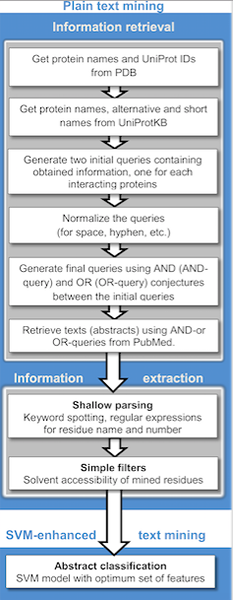
Wydobycie tekstowe, zwane również wydobywaniem danych tekstowych, to proces wydobywania znaczących spostrzeżeń lub informacji z nieustrukturyzowanych danych tekstowych. Jest to subtyp eksploracji danych, który obejmuje tekst - jeden z najczęstszych typów danych w bazach danych. Podobnie jak eksploracja danych, ma na celu wyodrębnienie przydatnych informacji ze źródeł danych poprzez identyfikację i badanie wzorców danych w danych. Jednak w wydobywaniu tekstu źródła danych są ograniczone do tekstu. Filtuje duże ilości danych tekstowych i wyodrębnia odpowiedni potrzebujesz.
Wydobycie tekstowe wymaga struktury tekstu wejściowego, a następnie identyfikacji wzorców w strukturalnych danych oraz oceny i interpretacji wyników. Kluczowym elementem eksploracji tekstu jest kolekcja dokumentów, która obejmuje grupowanie dokumentów tekstowych. Zazwyczaj eksploracja tekstu obejmuje ekstrakcję słów kluczowych, klasyfikację i grupowanie, podsumowanie dokumentów, wykrywanie anomalii i trendów oraz strumienie tekstowe.
Różnica między wydobywaniem tekstu a wydobyciem danych
Oznaczający
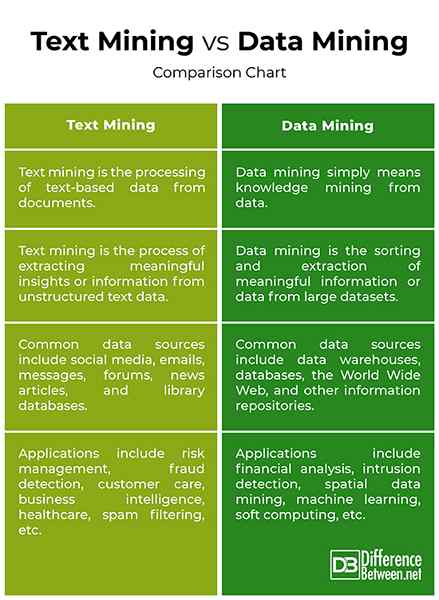
- Wydobycie danych to automatyczne przetwarzanie gromadzenia i analizy dużych ilości źródeł danych w celu znalezienia znaczących spostrzeżeń lub odkrycia ukrytych wzorców z danych w sposób, który dostarcza cennych informacji. Wydobycie danych oznacza po prostu wydobycie wiedzy na podstawie danych. Wydobycie tekstowe jest częścią eksploracji danych, która ma na celu wyodrębnienie przydatnych informacji ze źródeł danych poprzez identyfikację i badanie wzorców w danych tekstowych. Wydobycie tekstowe to przetwarzanie danych tekstowych z dokumentów.
Źródła danych
- Różne źródła danych wykorzystywane w procesie eksploracji danych obejmują hurtowary danych, światową sieć, transakcyjne bazy danych, multimedialne bazy danych, przestrzenne bazy danych, pliki płaskie i inne repozytoria informacyjne. Powszechnie używane źródła danych do eksploracji tekstu obejmują dane z takich źródeł, jak media społecznościowe, wiadomości e -mail, wiadomości, recenzje produktów, fora, artykuły, bazy danych bibliotek, skrobanie internetowe i tak dalej.
Metody wydobycia
- Najważniejszymi technikami eksploracji danych są gromadzenie i czyszczenie danych, przygotowanie danych, wzorce śledzenia, klasyfikacja, asocjacja, wykrywanie anomalii, analiza grupowania, analiza regresji i prognozowanie. Niektóre z najczęstszych technik wydobywania tekstu to pobieranie informacji, kategoryzacja tekstu, klasyfikacja i klastrowanie, podsumowanie dokumentów, analiza sentymentów, wykrywanie anomalii i trendów oraz strumienie tekstowe oraz strumienie tekstowe.
Wydobycie tekstowe vs. Wydobycie danych: wykres porównawczy
Streszczenie
Wydobycie danych oznacza sortowanie i ekstrakcję znaczących informacji lub danych z dużych zestawów danych w celu odkrycia wiedzy. Istnieje wiele terminów o podobnym znaczeniu, na przykład eksploracja wiedzy z danych, odkrywanie wiedzy, ekstrakcja wiedzy, analiza danych/wzorców itd. Obejmuje identyfikację trendów lub wzorców w danych, które zwykle wykraczają poza proste procedury analizy za pomocą algorytmów oprogramowania i metod statystycznych. Z drugiej strony wydobycie tekstu opiera się na różnych podejść do eksploracji danych w celu identyfikacji trendów w danych, z wyjątkiem eksploracji tekstu, analiza danych opiera się na gromadzeniu dokumentów. Wykorzystuje wiedzę podstawową w znacznie większym stopniu niż wydobycie danych.
Co to jest wydobycie tekstu z przykładami?
Wydobycie tekstowe identyfikuje ukryte wzorce w niewykorzystanych danych tekstowych i przekształcenie tych źródeł danych w możliwe do przyjęcia spostrzeżenia. Przykłady wydobycia tekstu obejmują ankiety klientów, recenzje online, zarządzanie ryzykiem, inteligencję biznesową, wykrywanie oszustw itp.
Jaka jest różnica między wydobywaniem tekstu a NLP?
Podczas gdy oba mają klucz do odblokowania wartości biznesowej w dużych zestawach danych, NLP koncentruje się na uczynieniu komputerów do zrozumienia ludzkich zachowań poprzez tekst, mowę, sentymenty i działania. Wydobycie tekstowe po prostu wyodrębnia znaczące spostrzeżenia lub informacje z nieustrukturyzowanych danych tekstowych.
Czy NLP jest wydobywaniem danych?
NLP jest elementem wydobywania tekstu, który pomaga komputerom w przetwarzaniu i analizowaniu dużych ilości danych naturalnych. Ma na celu wyodrębnienie informacji z tekstu, takich jak eksploracja tekstu. NLP i eksploracja danych są niezbędnymi elementami w nauce danych.
Jakie są porównanie między wydobywaniem tekstu i wydobywania danych internetowych?
Wydobycie danych jest zbiorowym terminem zarówno dla wydobywania tekstu, jak i wydobywania internetowego. Wydobycie danych oznacza po prostu wydobycie wiedzy na podstawie danych; Wydobycie tekstowe wyodrębnia znaczące spostrzeżenia lub informacje z nieustrukturyzowanych danych tekstowych; a wydobycie internetowe jest używanie technik eksploracji danych do odkrywania ukrytych wzorców z sieci World Web.