

Różnica między planowaniem zapobiegawczym i nie sprykowanym w systemach operacyjnych
- 2550
- 211
- Krystyna Urbanowicz
Planowanie procesora (Lub Planowanie procesora) określa, które procesy są przypisane i usunięte z procesora, na podstawie modeli planowania, takich jak Dotyczący pierwokupu I Planowanie nie spryskowe (znany również jako Planowanie spółdzielcze).
Starsze systemy mogą działać w prostych samodzielnych trybach, ale wraz ze wzrostem potrzeby responsywnych, elastycznych systemów, a także wirtualizacji, skuteczne zarządzanie wieloma przetwarzaniem zapewnia szybką reakcję na wszystkie żądania przetwarzania zadań.
Jednostki planowania są często określane jako zadanie I zadaniem planowania jest uruchamianie i zarządzanie tymi zadaniami w dowolnym momencie; Harmonogram wybiera zadanie do usunięcia i przypisania do procesora w celu przetworzenia, zgodnie z zastosowanym modelem planowania.
Skąd harmonogram wie, które zadania są priorytetem?
Harmonogram musi uruchomić sprawiedliwy i wydajny proces selekcji, biorąc pod uwagę zmienną, żądania dynamicznego przetwarzania i jak najlepiej wykorzystać cykle procesora.
Zadania mogą być w dwóch stanach podczas przetwarzania:
- W Rozbuchaj procesora W przypadku, gdy procesor wykonuje obliczenia w celu przetworzenia zadania (okres dla serii procesora różni się w zależności od zadania i programu do programu).
- W Rozsąd wejściowy/wyjściowy (I/O) Oczekiwanie na otrzymanie lub wysyłanie danych z systemu.
Gdy procesor jest bezczynny, harmonogram odczytuje Gotowa kolejka, i wybiera następne zadanie do wykonania. Następnie jest to Dyspozytor To daje wybraną kontrolę zadania procesora, więc musi być szybki! Za każdym razem, gdy dyspozytor jest znany jako Opóźnienie wysyłki.
Istnieją różne struktury i parametry niestandardowe do zdefiniowania Gotowa kolejka, a także kilka metod, które można wykorzystać do zarządzania złożonością procesu planowania.
Ogólnie rzecz biorąc, chodzi o optymalizację i maksymalizację wykorzystania procesora, przepustowość itp.
Harmonogram musi podjąć decyzję podczas jednego z następujących etapów:
- Kiedy zadanie się zmienia z a Działanie do Oczekiwanie (Na przykład oczekiwanie podczas żądania we/wy).
- Kiedy zadanie się zmienia z Działanie Do Gotowy (na przykład reagowanie na przerwanie).
- Kiedy zadanie się zmienia z Czekanie Do Gotowy (Na przykład żądanie we/wy zostało zakończone).
- Kiedy Zadanie
Nowe zadanie musi zostać wybrane, jeśli zdarzy się etap 1 lub 4, aby zapewnić pełne wykorzystanie procesora, aw etapie 2 i 3 zadanie może kontynuować działanie lub wybrane jest nowe.
Po zrozumieniu, w jaki sposób zadanie jest przetwarzane, spójrzmy na dwa modele harmonogramu, które dotyczą przerwy w CPU.
Oba mają podobne cechy z zadaniami, stanami zadaniowymi, kolejek i priorytetem (statyczne lub dynamiczne):
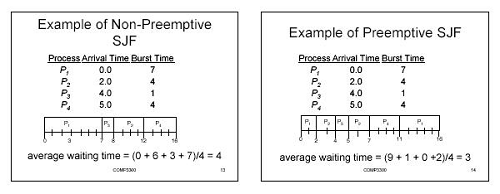
- Planowanie nie spryskowe Jest wtedy, gdy zadanie działa, dopóki nie zatrzyma się (dobrowolnie) lub zakończy. Windows® miał nie spryteczne planowanie do systemu Windows 3.x, po czym zmienił się na zapobiegawczy z systemu Windows 95.
- Planowanie zapobiegawcze W miejscu, w którym zadanie może być przymusowo zawieszone przez przerwanie procesora.
Planowanie nie spryskowe
Zadania w systemie nie sprykowanym będą działać do czasu zakończenia.
Harmonogram następnie sprawdza wszystkie stany zadań i planuje kolejne zadanie o najwyższym priorytecie z Gotowy państwo.
W przypadku nieudanych planów, gdy zadanie ma przypisanie do procesora, nie można go odebrać, nawet jeśli krótkie zadania muszą czekać na dłuższe zadania do wykonania.
Zarządzanie planowaniem we wszystkich zadaniach jest „uczciwe”, a czasy reakcji są przewidywalne, ponieważ zadania o wysokim priorytecie nie mogą podnieść zadań oczekiwania na kolejkę.
Planator zapewnia, że każde zadanie otrzyma „udział w procesorze, unikając opóźnień z jakimkolwiek zadaniem. „Ilość czasu” przydzielona na procesor niekoniecznie może być równy, ponieważ zależy to od tego, jak długo trwa zadanie.
Planowanie zapobiegawcze
Ten model harmonogramu umożliwia przerywanie zadań-w przeciwieństwie do harmonogramu nie sprycia, które ma podejście „odbiegające do ukończenia”.
Przerwy, które można zainicjować z połączeń zewnętrznych, wywołują harmonogram, aby zatrzymać działające zadanie zarządzania innym zadaniem o wyższym priorytecie - aby kontrolować procesor można zapobiegać.
Najwyższe priorytetowe zadanie w Gotowy Stan jest wykonywany, umożliwiając szybką reakcję na wydarzenia w czasie rzeczywistym.
Niektóre wady z planowaniem zapobiegawczym obejmują wzrost kosztów ogólnych zasobów podczas korzystania z przerw i problemów z dwoma zadaniami dzielącymi dane, ponieważ jeden może zostać przerwany podczas aktualizacji udostępnionych struktur danych i może negatywnie wpłynąć na integralność danych.
Z drugiej strony praktyczne jest, aby móc zatrzymać zadanie, aby zarządzać innym, które może być krytyczne.
W podsumowaniu
Można zdefiniować wiele wariancji i zależności w różnych zasadach, na przykład przy użyciu „Polityka rundy [i]” gdzie każde zadanie (z równym priorytetem) działa raz, a następnie umieszcza na końcu kolejki, w następnym cyklu.
Inne zasady obejmują Po pierwsze w pierwszym miejscu, Najkrótszy topin, Najkrótszy topnik, Najkrótszy pozostały czas, itp.
Analiza danych historycznych może dostarczyć informacji na temat aspektów, takich jak szybkość, z jaką przybywają nowe zadania, wybuchy procesora i we/wy ETC, więc rozkłady prawdopodobieństwa mogą obliczyć charakterystykę czasów oczekiwania zadań, a tym samym uzbrojenie administratorów odpowiednimi danymi w celu zdefiniowania modeli planowania.