

Różnica między ORC a parkietem
- 1234
- 363
- Patrycy Ziółkowski
Zarówno ORC, jak i Parquet są popularnymi formatami pamięci plik z kolumnami open source w ekosystemie Hadoop i są one dość podobne pod względem wydajności i prędkości, a przede wszystkim zostały zaprojektowane w celu przyspieszenia obciążeń analizy dużych danych. Praca z plikami ORC jest tak samo prosta, jak praca z plikami parkietowymi, ponieważ oferują wydajne możliwości odczytu i zapisu w stosunku do swoich odpowiedników opartych na wierszach. Oboje mają swój uczciwy udział w zaletach i wadach i trudno jest dowiedzieć się, który jest lepszy od drugiego. Przyjrzyjmy się na każdym z nich. Najpierw zaczniemy od ORC, a następnie przejdziemy do parkietu.
ORC
ORC, Short dla zoptymalizowanego kolumny wiersza, to bezpłatny i open-source kolumnowy format pamięci zaprojektowany dla obciążeń Hadoop. Jak sama nazwa wskazuje, ORC jest samozaptymalizowanym, zoptymalizowanym formatem plików, który przechowuje dane w kolumnach, które umożliwiają użytkownikom czytanie i dekompresowanie tylko potrzebnych elementów. Jest następcą tradycyjnego formatu kolumnowego pliku kolumnowego (RCFILE) zaprojektowanego w celu przezwyciężenia ograniczeń innych formatów plików Hive. Dostęp do danych zajmuje znacznie mniej czasu, a także zmniejsza wielkość danych do 75 procent. ORC zapewnia bardziej wydajny i lepszy sposób przechowywania danych do dostępu za pośrednictwem rozwiązań SQL-on-Hadoop, takich jak Hive za pomocą TEZ. ORC zapewnia wiele zalet w porównaniu z innymi formatami plików Hive, takich jak wysoka kompresja danych, szybsza wydajność, funkcja predykcyjna pchania i więcej, przechowywane dane są uporządkowane w paski, które umożliwiają duże, wydajne odczyty z HDFS.
Parkiet
Parquet to kolejny format plików zorientowany na otwarte źródło w ekosystemie Hadoop wspierany przez Cloudera, we współpracy z Twitterem. Parquet jest bardzo popularny wśród praktyków Big Data, ponieważ zapewnia mnóstwo optymalizacji przechowywania, szczególnie w zakresie prac analitycznych. Podobnie jak ORC, Parquet zapewnia uciśnięcia kolumnowe oszczędzające dużo miejsca do przechowywania, jednocześnie umożliwiając odczytanie poszczególnych kolumn zamiast odczytywania kompletnych plików. Zapewnia znaczące zalety w zakresie wymagań dotyczących wydajności i przechowywania w odniesieniu do tradycyjnych rozwiązań przechowywania. Jest bardziej wydajny w wykonywaniu operacji w stylu IO i jest bardzo elastyczny, jeśli chodzi o obsługę złożonej zagnieżdżonej struktury danych. W rzeczywistości jest szczególnie zaprojektowany, mając na uwadze zagnieżdżone struktury danych. Parquet jest również lepszym formatem plików w zmniejszaniu kosztów pamięci i przyspieszeniu kroku odczytu, jeśli chodzi o duże zestawy danych. Parquet działa naprawdę dobrze z Apache Spark. W rzeczywistości jest to domyślny format pliku do pisania i czytania danych w Spark.
Różnica między ORC a parkietem
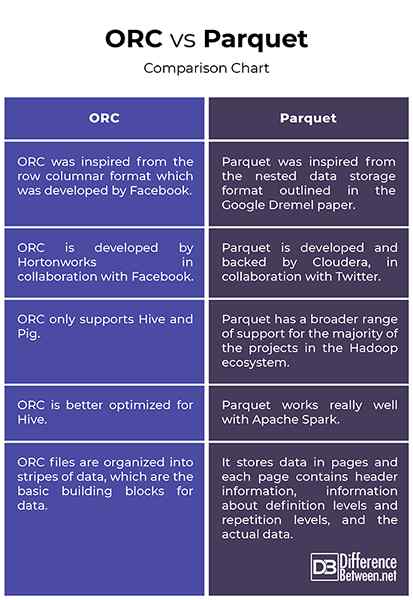
Pochodzenie
- ORC został zainspirowany formatem kolumnowym Row, który został opracowany przez Facebook w celu obsługi odczytów kolumnowych, predykcyjnych wypychania i leniwych odczytów. Jest następcą tradycyjnego formatu kolumnowego pliku kolumnowego (RCFILE) i zapewnia bardziej wydajny sposób przechowywania danych relacyjnych niż RCFILE, zmniejszając rozmiar danych nawet o 75 procent. Z drugiej strony Parquet został zainspirowany zagnieżdżonym formatem przechowywania danych przedstawiony w papierze Google Dremel i opracowany przez Cloudera, we współpracy z Twitterem. Parquet to teraz projekt inkubatora Apache.
Wsparcie
- Zarówno ORC, jak i Parquet są popularnymi formatami plików dużych danych, które udostępniają prawie podobny projekt, w którym oba udostępniają dane w kolumnach. Podczas gdy Parquet ma znacznie szerszy zakres wsparcia dla większości projektów w ekosystemie Hadoop, ORC wspiera jedynie Hive i Pig. Jedną kluczową różnicą między nimi jest to, że ORC jest lepiej zoptymalizowana pod kątem Hive, podczas gdy parkiet działa naprawdę dobrze z Apache Spark. W rzeczywistości Parquet to domyślny format pliku do pisania i czytania danych w Apache Spark.
Indeksowanie
- Praca z plikami ORC jest tak samo prosta, jak praca z plikami parkietowymi. Oba świetnie nadają się do ciężkich obciążeń. Jednak pliki ORC są zorganizowane w paski danych, które są podstawowymi elementami składowymi dla danych i są niezależne od siebie. Każdy pasek ma indeks, dane wierszowe i stopę. Stopka jest miejscem, w którym kluczowe statystyki dla każdej kolumny w pasku, takie jak hrabia, min, maks. I suma są buforowane. Z drugiej strony parkiet przechowuje dane na stronach, a każda strona zawiera informacje nagłówka, informacje o poziomach definicji i poziomach powtórzeń oraz rzeczywistych danych.
ORC vs. Parkiet: wykres porównawczy
Streszczenie
Zarówno ORC, jak i Parquet to dwa najpopularniejsze formaty przechowywania plików zorientowanych na otwarte źródło w ekosystemie Hadoop zaprojektowanym do dobrze pracy z obciążeniami analizy danych. Parquet został opracowany przez Cloudera i Twitter razem, aby rozwiązać problemy z przechowywaniem dużych zestawów danych za pomocą wysokich kolumn. ORC jest następcą tradycyjnej specyfikacji RCFILE, a dane przechowywane w formacie pliku ORC są zorganizowane w paski, które są wysoce zoptymalizowane dla operacji odczytu HDFS. Z drugiej strony parkiet jest lepszym wyborem pod względem zdolności adaptacyjnych, jeśli używasz kilku narzędzi w ekosystemie Hadoop. Parquet jest lepiej zoptymalizowany do użytku z Apache Spark, podczas gdy ORC jest zoptymalizowany do Hive. Ale w przeważającej części oba są dość podobne bez istotnych różnic między nimi.
- « Różnica między kwarantanną a samozadowoleniem
- Różnica między crowdsourcingiem a finansowaniem społecznościowym »