

Różnica między Hadoop i teradata
- 3916
- 1048
- Łukasz Kalisz
Teraz bardziej niż kiedykolwiek technologia odgrywa kluczową rolę w całym procesie tego, jak gromadzimy i wykorzystujemy dane. Technologia zmieniła sposób, w jaki dane są wytwarzane, przetwarzane i konsumowane. Ponieważ rynek analizy dużych zbiorów danych szybko się rozwija, wiele przedsiębiorstw i firm zaczyna inwestować w technologie Big Data w przechowywanie i analizę tych ogromnych ilości danych. Obecnie na rynku istnieje wiele technologii Big Data, które mają duży wpływ na nowe stosy technologii w celu obsługi dużych zbiorów danych. Jedną z takich technologii, która była w centrum rozmów Big Data, jest Apache Hadoop. Hadoop jest jedną z największych nazwisk w branży Big Data. Teradata to relacyjny system zarządzania bazą danych i wiodące rozwiązanie do hurtowni danych, które zapewnia rozwiązania zarządzania danymi dla analizy. Służy do przechowywania i przetwarzania dużej ilości strukturalnych danych w centralnym repozytorium. Poniżej znajduje się porównanie głowy do dwóch technologii.
Co to jest Hadoop?
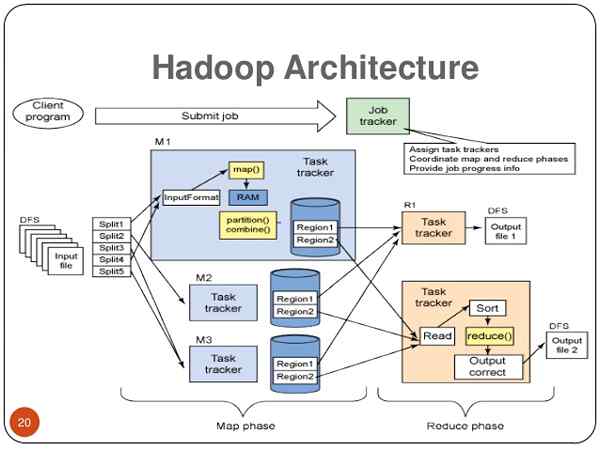
Hadoop jest sercem Big Data. Jest to struktura oprogramowania typu open source opracowana przez Apache Software Foundation i używana do przechowywania i przetwarzania różnorodnych typów danych, które umożliwiają przedsiębiorstwom opartym na danych szybkie uzyskanie pełnej wartości od wszystkich ich danych. Hadoop jest odpowiedzią na wdrożenie strategii dużych zbiorów danych. Oryginalnymi twórcami Hadoop są Doug Cutt i Mike Cafarella. Pracowali nad projektem, aby stworzyć duży indeks internetowy o nazwie „Nutch”. Widzieli dokumenty MapReduce i GFS z Google i uznali je za przydatne w projekcie. W końcu w końcu zintegrowali koncepcje z artykułów do projektu, który ostatecznie utworzył genezę projektu Hadoop. Doug nadał nazwę „Hadoop” swojemu zabawkowej słoniowi, którego później użył do swojego projektu open source. Hadoop przechowuje terabajty, a nawet petabajty danych niedrogie, bez utraty danych i przerywania analiz danych.

Co to jest teradata?
Teradata to relacyjny system zarządzania bazą danych, taki jak Oracle opracowany przez wiodącą firmę oprogramowania o tej samej nazwie. Teradata jest wiodącym na świecie dostawcą rozwiązań analitycznych biznesowych, rozwiązań danych i analiz oraz hybrydowych produktów i usług w chmurze. Zapewnia relacyjny system zarządzania bazą danych w jednym RDMS, który działa jako centralne repozytorium. Jego RDBM jest uważane za wiodące rozwiązanie do hurtowni danych, które prowadzi największe na świecie komercyjne bazy danych. Teradata zapewnia możliwości wspierania decyzji dla organizacji i przedsiębiorstw, które muszą przechowywać i analizować gigabajty, a nawet terabajty danych. Firma została zarejestrowana w 1979 roku i rozpoczęła się w garażu w Brentwood w Kalifornii. Nazwa teradata symbolizowała zdolność do zarządzania trylionami bajtów danych. Firma została założona przez grupę ludzi.
Różnica między Hadoop i teradata
Technologia
- Hadoop to technologia Big Data opracowana przez Apache Software Foundation do przechowywania i przetwarzania aplikacji dużych zbiorów danych na skalowalnych klastrach sprzętu towarowego. Jest to platforma typu open source, która zajmuje się wyzwaniami związanymi z dużymi zbiorami danych dotyczącymi ogromnych ilości danych, które są zbyt zróżnicowane i szybko zmieniające się w przypadku konwencjonalnych technologii i infrastruktury, aby skutecznie rozwiązać problem. Z drugiej strony teradata jest w pełni skalowalnym relacyjnym magazynem bazy danych zaimplementowanej w pojedynczych RDBMS, która działa jako centralne repozytorium. Jest to wiodące rozwiązanie do hurtowni danych, które prowadzi największe na świecie komercyjne bazy danych.
Architektura
- Hadoop opiera się na „architekturze mistrza-niewolnicy”, w której klaster składa się z jednego węzła głównego, a wszystkie pozostałe węzły są węzłami niewolnikami. Architektura Hadoop oparta jest na trzech podrzędnych: HDFS (Hadoop rozproszony system plików), MapReduce i Yarn (kolejny negocjator zasobów). HDFS jest częścią magazynu architektury Hadoop; MapReduce jest agentem, który rozpowszechnia pracę i zbiera wyniki; a przędza przydziela dostępne zasoby w systemie.
Teradata to architektura NIC NIC oparty na systemie masowo równoległym przetwarzaniu (MPP). Teradata DBMS jest liniowo i przewidywalnie skalowalny we wszystkich wymiarach obciążenia systemem bazy danych. Działa jako pojedynczy magazyn danych, który może akceptować dużą liczbę współbieżnych żądań z wielu aplikacji klienckich. Głównymi elementami teradata są parsing silnik, Bynet i wzmacniacze (procesory modułu dostępu).
Typ danych
- Hadoop służy do przechowywania i przetwarzania różnorodnych typów danych, które umożliwiają przedsiębiorstwa opartym na danych. Może przetwarzać dowolny rodzaj danych za pomocą wielu narzędzi open source-niezależnie od typu danych, niezależnie od tego, czy są to dane częściowo ustrukturyzowane, czy nieustrukturyzowane. Najwyższe możliwości Hadoopa do przetwarzania nieustrukturyzowanych danych są niezrównane. Z drugiej strony teradata jest relacyjnym rozwiązaniem do magazynowania danych najlepiej używanych do przechowywania i przetwarzania dużej ilości strukturalnych danych formatu tabelarycznego. Nie jest dobre do przetwarzania danych częściowo ustrukturyzowanych lub nieustrukturyzowanych.
Hadoop vs. Teradata: wykres porównawczy

Podsumowanie Hadoop vs. Teradata
Hadoop przechowuje terabajty, a nawet petabajty danych niedrogie, bez utraty danych… może przetwarzać dowolny rodzaj danych za pomocą wielu narzędzi open source. Z drugiej strony teradata to w pełni skalowalne relacyjne rozwiązanie do zarządzania bazą danych używane do przechowywania i przetwarzania dużej ilości strukturalnych danych w centralnym repozytorium. Hadoop opiera się na „architekturze mistrza-niewolnicy”, w której klaster zawiera pojedynczy węzeł główny, a wszystkie pozostałe węzły są węzłami niewolnikami, podczas gdy teradata jest architekturą nie udostępnioną opartą na masowo równoległym przetwarzaniu (MPP) systemowym (MPP) systemowym (MPP) systemowym (MPP).
- « Różnica między nadwyżką a niedoborem
- Różnica między mediami społecznościowymi a tradycyjnymi mediami »