

Różnica między Elasticsearch i Hadoop
- 4284
- 578
- Marta Ruciński
ElasticSearch to skalowalna, zorientowana na dokument wyszukiwarka zbudowana wokół Lucene, aby ułatwić wszystkie rodzaje wyszukiwania (w tym wyszukiwanie w pełnym teście) i analizy. Oprócz bycia wyszukiwarką, Elasticsearch to rozproszony, wielozadaniowy sklep z dokumentami. Hadoop to rozproszona struktura, która pozwala przechowywać i przetwarzać duże zbiory danych w środowisku rozproszonym w klastrach komputerów za pomocą prostych modeli programowania.
Co to jest ElasticSearch?
ElasticSearch to wysoce rozłożony, rozproszony pełny tekst wyszukiwania i analityczny, który umożliwia przechowywanie, wyszukiwanie i analizę dużych ilości danych w czasie rzeczywistym w czasie rzeczywistym. Chociaż zaczął się jako wyszukiwarka pełnotekstowa, zaczyna ewoluować jako silnik analityczny, który może obsługiwać złożone agregacje. Jest zbudowany na Lucene, bibliotece oprogramowania do wyszukiwarek napisanej w całości w Javie i obsługiwana przez Apache Software Foundation. Apache Lucene jest jedną z najczęściej używanych bibliotek do wyszukiwania. ElasticSearch ma charakter i jest bardzo łatwy w użyciu, co ułatwia rozpoczęcie i skalowanie, ponieważ masz więcej danych. Chociaż jest ono używane przede wszystkim jako wyszukiwarka, może być używany jako ramy analityczne za pośrednictwem potężnego systemu agregacji i przechowywania danych.
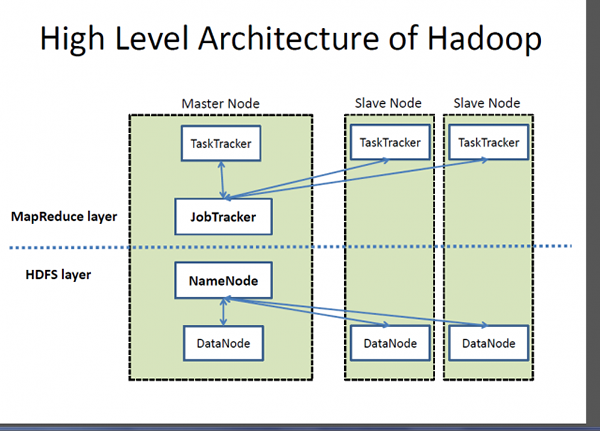
Co to jest Hadoop?
Hadoop jest wysoce skalowalnym, rozproszonym frameworkiem przetwarzania do zarządzania przetwarzaniem danych i przechowywania dużych zestawów danych działających w systemach klastrowych. Hadoop to zbiór narzędzi oprogramowania, który umożliwia przechowywanie i przetwarzanie dużych zbiorów danych oraz uruchamianie aplikacji klastrów sprzętu towarowego. Hadoop jest zarejestrowanym znakiem towarowym Fundacji Apache Software, która rozpoczęła się jako pojedynczy projekt oprogramowania do obsługi wyszukiwarki internetowej, ale ewoluował w ekosystem narzędzi i aplikacji używanych do analizy dużej ilości danych. Hadoop opiera się na modelu programowania MapReduce do przetwarzania ogromnych zestawów danych na klastrach sprzętu towarowego. Podstawowym elementem Hadoop jest Hadoop rozproszony system plików (HDFS), który jest równoległym systemem plików o wysokiej wydajności zaprojektowanym w celu zaspokojenia potrzeb przetwarzania dużych zbiorów danych, takich jak dostęp do strumieniowego strumieniowego strumieniowego.
Różnica między Elasticsearch i Hadoop
Narzędzie
- ElasticSearch to wysoce rozłożony, rozproszony pełny tekst wyszukiwania i analityczny, który umożliwia przechowywanie, wyszukiwanie i analizę dużych ilości danych w czasie rzeczywistym w czasie rzeczywistym. Chociaż jest ono używane przede wszystkim jako wyszukiwarka, może być używany jako ramy analityczne za pośrednictwem potężnego systemu agregacji i przechowywania danych. Z drugiej strony Hadoop to potężne rozproszone struktura przetwarzania, który rozpoczął się jako pojedynczy projekt oprogramowania do obsługi wyszukiwarki internetowej, ale ewoluował w ekosystem narzędzi i aplikacji używanych do analizy dużej ilości danych.
Architektura
- Hadoop to open source Framework, który śledzi główną architekturę niewolników do przechowywania danych i przetwarzania danych za pomocą odpowiednio systemu plików Hadoop (HDFS) i MapReduce Programming Model. HDFS to wysokowydajny równoległy system plików zaprojektowany w celu zaspokojenia potrzeb przetwarzania dużych zbiorów danych. Z drugiej strony ElasticSearch opiera się na architekturze REST i zapewnia punkty końcowe API do wykonywania operacji CRUD przez HTTP, a także do wykonywania zadań monitorowania klastrów. Pozwala to na integrację, zarządzanie danymi indeksowanymi i zapytaniami na kilka różnych sposobów.
Zasada
- ElasticSearch zapewnia pełne DSL zapytania oparte na JSON, aby ujawnić moc Lucene do czytania i pisania zapytań w bardzo łatwy sposób. Większość magazynów danych NoSQL używa JSON do przechowywania swoich danych, ponieważ format JSON jest bardzo zwięzły, elastyczny i łatwy do zrozumienia. Z drugiej strony Hadoop opiera się na modelu programowania MapReduce do przetwarzania ogromnych zestawów danych na klastrach sprzętu towarowego. MapReduce to paradygmat programowania w ramach Hadoop, który służy do dostępu do ogromnych ilości danych przechowywanych na tysiącach serwerów w klastrze Hadoop.
Używać
- ElasticSearch to pełna wyszukiwarka tekstowa, która jest jego głównym użyciem, ale jest również używana jako ramy analityczne za pośrednictwem swojego potężnego systemu agregacji. Można go również wykorzystać jako bardzo potężny silnik analityczny do wykonywania wszystkich zapytań, które zwykle uruchamiasz w partii lub offline w czasie rzeczywistym. Obsługuje nie tylko wyszukiwanie, ale także złożone agregacje. Z drugiej strony Hadoop jest używany głównie jako narzędzie do przechowywania danych i uruchamiania aplikacji na klastrach sprzętu towarowego za pomocą najbardziej niezawodnego systemu pamięci masowej na świecie, HDFS.
ElasticSearch vs. Hadoop: wykres porównawczy
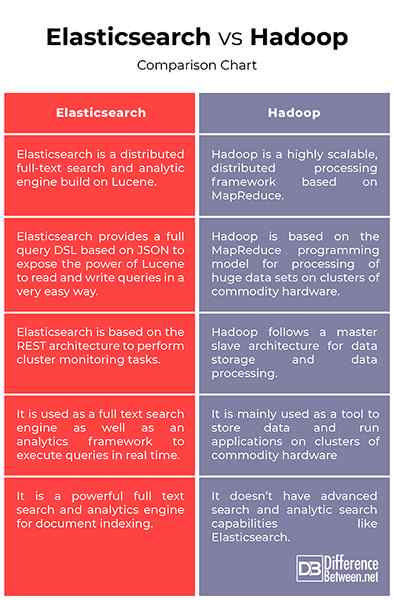
Podsumowanie elasticsearch vs. Hadoop:
ElasticSearch jest potężnym narzędziem do pełnego wyszukiwania tekstu i indeksowania dokumentów kompilacja na szczycie Lucene, biblioteki oprogramowania do wyszukiwarek napisanej całkowicie w Javie, podczas gdy Hadoop jest ramą przetwarzania danych do obsługi dużych ilości danych w ułamku sekund. Hadoop opiera się na popularnym modelu programowania MapReduce do przetwarzania ogromnych zestawów danych na klastrach sprzętu towarowego. ElasticSearch to potężny silnik analityczny do zarządzania całym potokiem analitycznym, podczas gdy Hadoop jest ramą do obsługi dowolnego agregacji danych lub transformacji.
- « Różnica między wypełniaczami a botoksem
- Różnica między Gwardią Narodową a Rezerwat Sił Powietrznych »