

Różnica między przetwarzaniem w chmurze a przetwarzaniem krawędzi
- 1156
- 233
- Marta Ruciński
Obliczenia w chmurze dramatycznie zmieniło sposób, w jaki żyjemy, pracujemy i studiujemy od momentu powstania. Teraz przetwarzanie w chmurze jest nowym modnym hasłem w technologii informacyjnej i rośnie z dnia na dzień. Firmy i organizacje już przeniosły swoje zadania obliczeniowe do chmury, co okazało się skutecznym sposobem przechowywania i przetwarzania danych. Jednak przetwarzanie w chmurze nie jest wystarczająco wydajne, aby obsłużyć rosnącą ilość danych generowanych przez Internet przedmiotów (IoT). Co można zrobić, aby przezwyciężyć ograniczenia obecnej architektury zorientowanej na chmurę?
Odpowiedź to przetwarzanie krawędzi. Dzisiaj obliczenia migruje z serwera lokalnego na serwer chmurowy, a teraz stopniowo z chmury do serwera Edge, na którym dane są gromadzone z punktu początkowego. Obliczanie krawędzi przesuwa infrastrukturę obliczeniową bliżej źródła danych, w której jest potrzebne, aby zapewnić szybki dostęp. Porównujemy dwa modele obliczeniowe, aby zrozumieć, w jaki sposób niektóre problemy w modelu przetwarzania w chmurze mogą zostać rozwiązane przez paradygmat obliczeń krawędzi.
Co to jest przetwarzanie w chmurze?
Obliczanie w chmurze to dostarczanie zasobów obliczeniowych na żądanie, w tym serwery, pamięci, bazy danych i oprogramowania przez Internet, a nie serwer lokalny lub komputer osobisty. Cloud to rozproszona platforma technologiczna, która wykorzystuje wyrafinowane innowacje technologiczne, aby zapewnić wysoce skalowalne środowiska, które mogą być zdalnie wykorzystane przez firmy lub organizacje na wiele sposobów. Firmy przeniosły się do chmury, aby uzyskać lepszą skalowalność, mobilność i bezpieczeństwo. Chmura zapewnia kompleksowe mechanizmy przechowywania, przetwarzania i zarządzania. Firmy mogą uniknąć kosztów z góry i złożoności utrzymania własnej infrastruktury IT, a po prostu płacą za to, czego używają, a kiedy z nich korzystają. Niektórzy z głównych dostawców usług w chmurze to Google, Oracle, Microsoft, IBM, Cisco, Verizon i Rackspace. Przykładem przetwarzania w chmurze jest Microsoft Azure.
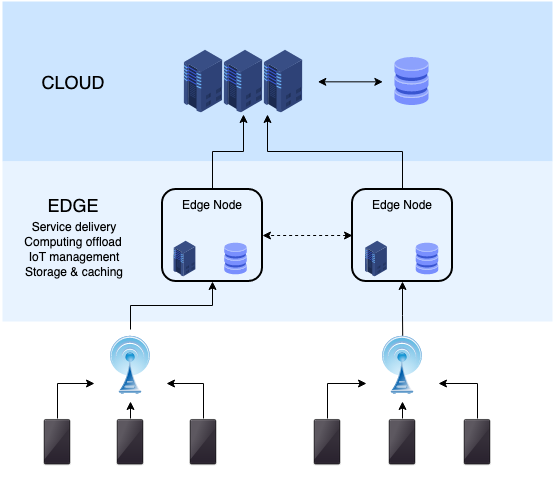
Co to jest przetwarzanie krawędzi?
Edge Computing to rozproszony paradygmat obliczeń, który zbliża obliczenia do krawędzi sieci, w przeciwieństwie do konwencjonalnej struktury przetwarzania w chmurze. Chodzi o rozszerzenie przetwarzania w chmurze na bardziej geo-dystrybuowany sposób, w jaki zasoby obliczeniowe, sieciowe i przechowywania mogą być dystrybuowane w różnych lokalizacjach. Celem przetwarzania krawędzi jest to, że obliczanie powinno odbywać się w pobliżu źródeł danych. W obliczeniach krawędzi rzeczy działają nie tylko jako konsumenci danych, ale także grają jako producenci danych. Edge Computing odegrał ważną rolę w przezwyciężeniu złożoności w przetwarzaniu w chmurze - pobliskie urządzenia są używane jako serwery do świadczenia lepszych usług. Dzieli pomysł przeniesienia obliczeń bliżej urządzeń Edge, aby przezwyciężyć ograniczenia, takie jak przepustowość, opóźnienie i wysokie koszty w tradycyjnym przetwarzaniu w chmurze.
Różnica między przetwarzaniem w chmurze a przetwarzaniem krawędzi
Definicja
- Obliczanie w chmurze to dostarczanie zasobów obliczeniowych na żądanie, w tym serwery, pamięci, bazy danych i oprogramowania przez Internet, a nie serwer lokalny lub komputer osobisty. Słowo „chmura” to metafora Internetu i „przetwarzania w chmurze” to rodzaj przetwarzania internetowego, co oznacza przechowywanie i dostęp do danych i programów przez Internet. Z drugiej strony przetwarzanie krawędzi odnosi się do wdrażania obsługi danych lub innych operacji sieciowych z dala od serwerów chmurowych i w kierunku krawędzi sieci, w której dane są gromadzone z punktu pochodzenia Konwencjonalne przetwarzanie w chmurze.
Architektura
- Architektura przetwarzania w chmurze odnosi się do wielu luźno sprzężonych komponentów i podrzędnych wymaganych do przetwarzania w chmurze. Definiuje elementy i relacje między nimi. Obliczanie w chmurze to dostarczanie infrastruktury IT i aplikacji jako usługi na podstawie wynagrodzeń jako dla osób fizycznych i organizacji za pośrednictwem platform internetowych. Edge Computing to rozszerzenie konwencjonalnego przetwarzania w chmurze, opracowując rozproszony paradygmat obliczeń, który zbliża aplikacje i dane do krawędzi sieci w kierunku źródeł przechwytywania danych, aby rozwiązać takie problemy, jak czas odpowiedzi, bezpieczeństwo danych i energia zasilania konsumpcja.
Korzyści
- W obliczeniach krawędzi rzeczy działają nie tylko jako konsumenci danych, ale także grają jako producenci danych. Ułatwia działanie usług obliczeniowych, pamięci masowej i sieciowej między urządzeniami końcowymi a centrami danych przetwarzania w chmurze. Chmura wymaga dużo przepustowości, a sieci bezprzewodowe mają ograniczenia. Ale w przypadku przetwarzania krawędzi ilość przepustowości jest znacznie zmniejszona. Ponieważ pobliskie urządzenia są używane jako serwery, większość problemów, takich jak zużycie energii, bezpieczeństwo i czas reakcji, jest rozwiązywana skutecznie i skutecznie. Obliczanie krawędzi służy do zwiększenia ogólnej wydajności IoT.
Przetwarzanie w chmurze vs. Obliczenie krawędzi: wykres porównawczy

Streszczenie
Chmura zapewnia kompleksowe mechanizmy przechowywania, przetwarzania i zarządzania. Jednak przetwarzanie w chmurze nie jest wystarczająco wydajne, aby obsłużyć rosnącą ilość danych generowanych przez Internet przedmiotów (IoT). Tutaj przychodzi do obrazu przetwarzania krawędzi. Obliczenie krawędzi przesuwa infrastrukturę obliczeniową bliżej źródła danych, w którym jest to potrzebne, aby rozwiązać takie problemy, jak czas odpowiedzi, bezpieczeństwo danych i zużycie energii. Podobnie jak przetwarzanie w chmurze, przetwarzanie Edge zapewnia obliczenia, pamięć i aplikacje do zużycia przez użytkowników końcowych. Jednak przetwarzanie krawędzi ma znacznie większy rozkład geograficzny i większą bliskość użytkowników końcowych.