

Różnica między workami a losowym lasem
- 1970
- 198
- Pani — Jóźwiak
Z biegiem lat wiele systemów klasyfikatorów, zwanych także systemami Ensemble, było popularnym tematem badawczym i cieszył się rosnącą uwagą w społeczności inteligencji obliczeniowej i uczenia maszynowego. Przyciągnęło zainteresowanie naukowców z kilku dziedzin, w tym uczenia maszynowego, statystyki, rozpoznawania wzorców i odkrywania wiedzy w bazach danych. Z czasem metody zespołu okazały się bardzo skuteczne i wszechstronne w szerokim spektrum domen problemowych i zastosowaniach w świecie rzeczywistym. Pierwotnie opracowane w celu zmniejszenia wariancji zautomatyzowanego systemu decyzyjnego, od tego czasu metody zespołu zostały wykorzystane do rozwiązywania różnych problemów z uczeniem maszynowym. Przedstawiamy przegląd dwóch najwybitniejszych algorytmów zespołowych - workowania i losowego lasu - a następnie omawiamy różnice między nimi.
W wielu przypadkach worki, które wykorzystują pobieranie próbek bootstrap, wykazano, że warkocz klasyfikacji ma wyższą dokładność niż pojedyncze drzewo klasyfikacyjne. Bagging jest jednym z najstarszych i najprostszych algorytmów opartych na zespole, które można zastosować do algorytmów opartych na drzewach w celu zwiększenia dokładności prognoz. Istnieje jeszcze jedna ulepszona wersja worków o nazwie Random Forest Algorytm, który jest zasadniczo zespołem drzew decyzyjnych wyszkolonych z mechanizmem workowania. Zobaczmy, jak działa losowy algorytm lasu i jak się różni od worków w modelach zespołów.
Parcianka
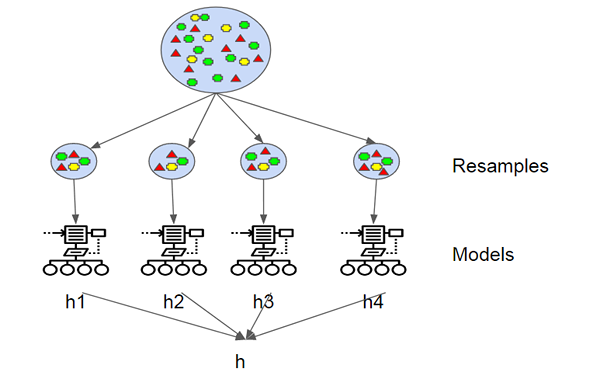
Agregacja bootstrap, znana również jako worka, jest jednym z najwcześniejszych i najprostszych algorytmów opartych na zespole do zwiększania solidnych drzew decyzyjnych i lepszej wydajności. Koncepcją workowania polega na połączeniu prognoz kilku podstawowych uczniów w celu stworzenia dokładniejszej wydajności. Leo Breiman wprowadził algorytm workowania w 1994 roku. Wykazał, że agregacja bootstrap może przynieść pożądane wyniki w niestabilnych algorytmach uczenia się, w których niewielkie zmiany w danych szkoleniowych mogą powodować duże zmiany prognoz. Bootstrap to próbka zestawu danych z wymianą, a każda próbka jest generowana przez równomierne próbkowanie zestawu treningowego wielkości M, aż do uzyskania nowego zestawu z instancjami M.
Losowy las
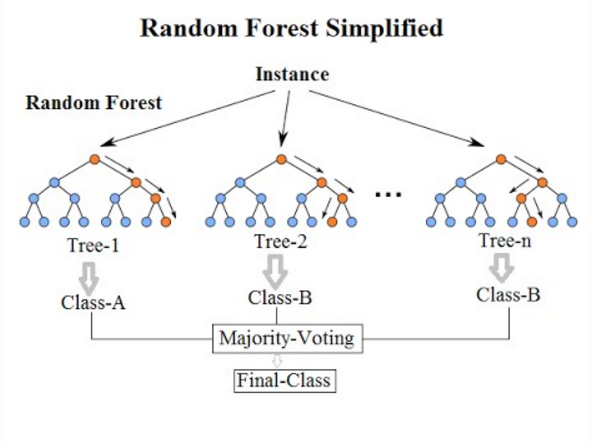
Random Forest jest nadzorowanym algorytmem uczenia maszynowego opartego na uczeniu się zespołów i ewolucji oryginalnego algorytmu Breimana. Jest to świetna poprawa w stosunku do workowanych drzew decyzyjnych w celu zbudowania wielu drzew decyzyjnych i agregowania ich, aby uzyskać dokładny wynik. Breiman dodał dodatkową losową zmienność do procedury workowania, tworząc większą różnorodność wśród uzyskanych modeli. Losowe lasy różnią się od worków, zmuszając drzewo do użycia tylko podzbioru dostępnych predyktorów do podziału w fazie wzrostu. Wszystkie drzewa decyzyjne, które tworzą losowy las, są różne, ponieważ każde drzewo jest zbudowane na innym losowym podzbiorze danych. Ponieważ minimalizuje nadmierne dopasowanie, jest ono bardziej dokładne niż jedno drzewo decyzyjne.
Różnica między workami a losowym lasem
Podstawy
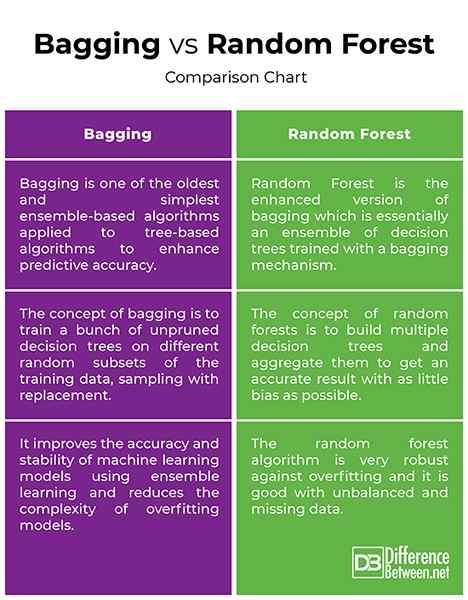
- Zarówno lasy workowate, jak i losowe są algorytmami opartymi na zespole, które mają na celu zmniejszenie złożoności modeli, które nadmiernie przygotowują dane treningowe. Agregacja bootstrap, zwana także workami, jest jedną z najstarszych i potężnych metod zespołowych, aby zapobiec nadmiernemu dopasowaniu. Jest to meta-technika, która wykorzystuje wiele klasyfikatorów w celu poprawy dokładności predykcyjnej. Worka oznacza po prostu wyciągnięcie losowych próbek z próbki treningowej do wymiany w celu uzyskania zespołu różnych modeli. Random Forest jest nadzorowanym algorytmem uczenia maszynowego opartego na uczeniu się zespołów i ewolucji oryginalnego algorytmu Breimana.
Pojęcie
- Koncepcja próbkowania bootstrap (worka) polega na szkoleniu grupy nieudanych drzew decyzyjnych na różnych losowych podgrupach danych szkoleniowych, próbkowaniu z wymianą, w celu zmniejszenia wariancji drzew decyzyjnych. Chodzi o połączenie prognoz kilku podstawowych uczniów w celu stworzenia dokładniejszej wydajności. W przypadku losowych lasów do procedury workowania dodaje się dodatkową różnorodność losową. Ideą losowych lasów jest zbudowanie wielu drzew decyzyjnych i agregowanie ich, aby uzyskać dokładny wynik.
Bramka
- Zarówno drzewa workowane, jak i losowe lasy są najczęstszymi instrumentami uczenia się zespołu używanymi do rozwiązywania różnych problemów z uczeniem maszynowym. Próbkowanie bootstrap to meta-algorytm zaprojektowany w celu poprawy dokładności i stabilności modeli uczenia maszynowego za pomocą uczenia się zespołów i zmniejszenia złożoności modeli nadmiernego dopasowania. Losowy algorytm lasu jest bardzo solidny w stosunku do nadmiernego dopasowania i jest dobry w przypadku niezrównoważonych i brakujących danych. Jest to również preferowany wybór algorytmu do budowania modeli predykcyjnych. Celem jest zmniejszenie wariancji poprzez uśrednienie wielu głębokich drzew decyzyjnych, przeszkolonych na różnych próbkach danych.
Worka vs. Losowy las: wykres porównawczy
Streszczenie
Zarówno drzewa workowane, jak i losowe lasy są najczęstszymi instrumentami uczenia się zespołu używanymi do rozwiązywania różnych problemów z uczeniem maszynowym. Bagging jest jednym z najstarszych i najprostszych algorytmów opartych na zespole, które można zastosować do algorytmów opartych na drzewach w celu zwiększenia dokładności prognoz. Z drugiej strony losowe lasy są nadzorowanym algorytmem uczenia maszynowego i ulepszoną wersją modelu próbkowania Bootstrap używanego zarówno do problemów z regresją, jak i klasyfikacją. Ideą losowego lasu jest zbudowanie wielu drzew decyzyjnych i agregowanie ich, aby uzyskać dokładny wynik. Losowy las jest zwykle dokładniejszy niż jedno drzewo decyzyjne, ponieważ minimalizuje nadmierne dopasowanie.