

Różnica między przetwarzaniem siatki a przetwarzaniem w chmurze
- 1057
- 64
- Spirydion Kruk
Przetwarzanie siatki i przetwarzanie w chmurze są koncepcyjnie podobne, które można łatwo pomylić. Pojęcia są dość podobne i oba mają tę samą wizję świadczenia usług użytkownikom poprzez udostępnianie zasobów między dużą pulą użytkowników.
Oba są oparte na technologii sieciowej i są zdolne do wielozadaniowego znaczenia użytkownicy mogą uzyskać dostęp do pojedynczych lub wielu instancji aplikacji, aby wykonywać różne zadania.
Podczas gdy przetwarzanie siatki obejmuje wirtualizację zasobów obliczeniowych do przechowywania ogromnych ilości danych, podczas gdy przetwarzanie w chmurze to miejsce, w którym aplikacja nie uzyskuje dostępu bezpośrednio w zasobach, a raczej uzyskuje dostęp do usługi przez Internet.
W obliczeniach sieci zasoby są dystrybuowane przez siatki, podczas gdy w przetwarzaniu w chmurze zasoby są zarządzane centralnie. Rzućmy okiem na dwie technologie komputerowe.
Co to jest przetwarzanie siatki?
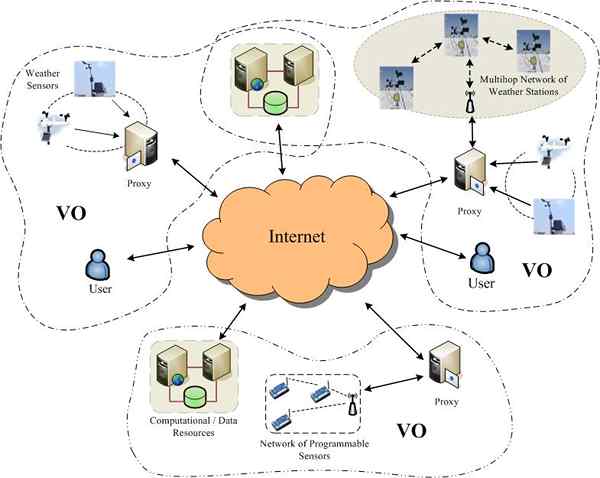
Obliczanie siatki to sieciowy model obliczeniowy, który ma możliwość przetwarzania dużych objętości danych za pomocą grupy komputerów sieciowych, które koordynują razem, aby rozwiązać problem.
Zasadniczo jest to ogromna sieć połączonych komputerów pracujących nad wspólnym problemem, dzieląc go na kilka małych jednostek zwanych siatkami. Opiera się na rozproszonej architekturze, co oznacza, że zadania są zarządzane i planowane w sposób rozproszony bez zależności.
Grupa komputerów działa jako wirtualny superkomputer w celu zapewnienia skalowalnego i bezproblemowego dostępu do zasobów obliczeniowych szerokiego obszaru, które są dystrybuowane geograficznie i przedstawiają je jako pojedyncze, ujednolicone zasoby do wykonywania dużych aplikacji, takich jak analiza ogromnych zestawów danych danych.
Co to jest przetwarzanie w chmurze?
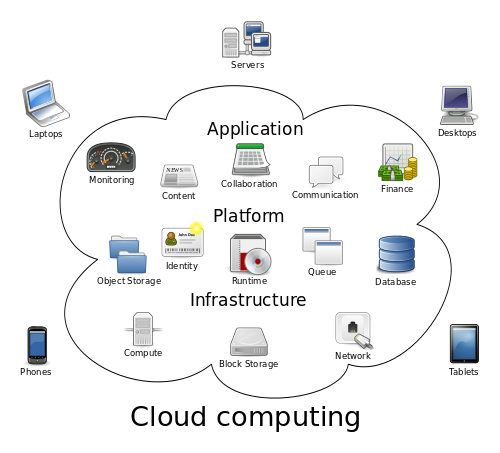
Obliczanie w chmurze to rodzaj obliczeń internetowych, w których aplikacja nie uzyskuje dostępu do zasobów bezpośrednio, raczej tworzy ogromną pulę zasobów za pośrednictwem wspólnych zasobów. Jest to nowoczesny paradygmat obliczeń oparty na technologii sieciowej, która jest specjalnie zaprojektowana do zdalnie dostarczania skalowalnych i mierzonych zasobów informatycznych.
Umożliwia dostęp na żądanie do wspólnej puli dynamicznie skonfigurowanych zasobów obliczeniowych i usług wyższego poziomu, eliminując w ten sposób potrzebę ogromnych inwestycji w lokalną infrastrukturę. Zasoby obliczeniowe są zarządzane centralnie, które znajdują się na wielu serwerach w klastrach. Użytkownicy mogą uzyskać dostęp do oprogramowania i aplikacji z dowolnego miejsca, nie martwiąc się o przechowywanie własnych danych. Po prostu załamuje się na „płacić tylko za to, czego potrzebujesz”.
Różnica między przetwarzaniem siatki a przetwarzaniem w chmurze
-
Technologia zaangażowana w przetwarzanie sieci i przetwarzanie w chmurze
- Obliczanie sieci to forma obliczeń, która następuje po rozproszonej architekturze, co oznacza, że pojedyncze zadanie jest podzielone na kilka mniejszych zadań za pośrednictwem systemu rozproszonego z wieloma sieciami komputerowymi. Z drugiej strony przetwarzanie w chmurze to zupełnie nowa klasa obliczeń oparta na technologii sieciowej, w której każdy użytkownik chmury ma własne prywatne zasoby, które jest dostarczane przez konkretnego dostawcę usług.
-
Terminologia obliczeń siatki i obliczeń w chmurze
- Oba są sieciami komputerowymi opartymi na sieci, które mają podobne cechy, takie jak pula zasobów, jednak bardzo różnią się od siebie pod względem architektury, modelu biznesowego, interoperacyjności itp. Przetwarzanie sieci to zbiór zasobów komputerowych z wielu lokalizacji w celu przetworzenia jednego zadania. Grid działa jako system rozproszony do wspólnego dzielenia się zasobami. Z drugiej strony przetwarzanie w chmurze jest formą przetwarzania opartego na zwirtualizowanych zasobach, które znajdują się w wielu lokalizacjach w klastrach.
-
Obliczanie zasobów w przetwarzaniu siatki i przetwarzaniu w chmurze
- Obliczanie sieci oparte jest na systemie rozproszonym, co oznacza, że zasoby obliczeniowe są rozmieszczone między różnymi jednostkami obliczeniowymi, które znajdują się w różnych miejscach, krajach i kontynentach. W przetwarzaniu w chmurze zasoby obliczeniowe są zarządzane centralnie, które znajdują się na wielu serwerach w klastrach w prywatnych centrach danych dostawców chmur.
-
Społeczność badawcza
- W obliczeniach sieciowych zasoby obliczeniowe są dostarczane jako narzędzie z siatkami jako platforma komputerowa, która jest dystrybuowana geograficznie i jest grupowana w organizacji wirtualnej z wieloma społecznościami użytkowników w celu rozwiązania problemów na dużą skalę przez Internet. Siatka obejmuje więcej zasobów niż tylko komputery i sieci. Z drugiej strony przetwarzanie w chmurze obejmuje wspólną grupę administratorów systemów, którzy zarządzają całą domeną.
-
Funkcja obliczeń siatki i przetwarzania w chmurze
- Główną funkcją przetwarzania siatki jest planowanie zadań przy użyciu wszelkiego rodzaju zasobów obliczeniowych, w których zadanie jest podzielone na kilka niezależnych podrzędnych, a każda maszyna na siatce jest przypisywana zadaniem. Po zakończeniu wszystkich podrzędnych podległych są one odesłane z powrotem do głównej maszyny, która obsługuje i przetwarza wszystkie zadania. Obliczanie w chmurze obejmuje łączenie zasobów poprzez grupowanie zasobów na podstawie potrzebnych z klastrów serwerów.
-
Zastosowanie przetwarzania siatki i przetwarzania w chmurze
- Termin „chmura” odnosi się do Internetu w przetwarzaniu w chmurze, a jako całość oznacza przetwarzanie internetowe. Chmura zarządza danymi, wymaganiami bezpieczeństwa, kolejkami pracy itp. eliminując potrzeby i złożoność kupowania sprzętu i oprogramowania potrzebnego do tworzenia aplikacji, które mają być dostarczane jako usługa w chmurze. Obliczanie sieci są głównie wykorzystywane przez badania akademickie i jest w stanie obsłużyć duże zestawy o ograniczonym czasie pracy, które obejmują ogromne ilości danych.
Obliczanie siatki vs. Obliczanie w chmurze: wykres porównawczy

Podsumowanie obliczeń siatki vs. Chmura obliczeniowa
Zarówno obliczanie sieci, jak i przetwarzanie w chmurze są technologią obliczeniową opartą na sieci, które obejmują pulę zasobów, ale przetwarzanie w chmurze eliminuje złożoność kupowania sprzętu i oprogramowania do budowania aplikacji poprzez przydzielanie zasobów, które są umieszczane na wielu serwerach w klastrach.
Przeciwnie, obliczenia sieciowe to technologia obliczeniowa, która łączy zasoby obliczeniowe z różnych domen, aby osiągnąć wspólny cel.
Komputery w sieci pracują razem nad zadaniem i każdy komputer może uzyskać dostęp do zasobów każdego innego komputera w sieci.
Mówiąc prosto, przetwarzanie siatki to grupa połączonych komputerów, które współpracują w celu obsługi ogromnych ilości danych.
- « Różnica między hipersomnią a narkolepsją
- Różnica między przetwarzaniem w chmurze a wirtualizacją »